Péndulo y Física Diferenciable para Robótica#
![]()
En esta notebook vamos a modelar un péndulo forzado, simular su dinámica en el tiempo y usar gradientes para optimizar una secuencia de torques que lo lleve hacia posiciones objetivo.
La idea central es mostrar por qué un simulador diferenciable resulta útil en robótica: permite que el modelo físico, la trayectoria y el objetivo de control formen un único pipeline optimizable mediante Autograd.
Problema físico y objetivo de control#
Consideramos un péndulo simple de longitud L y masa m, cuyo estado está dado por el ángulo theta y la velocidad angular omega. Sobre la articulación puede aplicarse un torque de control u. La dinámica idealizada es
donde g es la gravedad y b representa un amortiguamiento viscoso simple.
El problema que queremos resolver es el siguiente: partir desde una condición inicial sencilla y encontrar una política de torques abierta (predefinida y que no depende del estado actual) \(u_0, \ldots, u_{T-1}\) que haga swing-up, es decir, que lleve el péndulo desde la posición colgante hasta la vertical invertida.
La física diferenciable entra en juego porque queremos derivar una función de costo con respecto a las acciones de control. Para eso, toda la simulación debe permanecer dentro del grafo computacional de PyTorch.
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import animation
from IPython.display import Image, display
import torch
from torch.autograd import grad
import os
%matplotlib inline
class PendulumModel:
def __init__(self, length=1.0, mass=1.0, gravity=9.81):
self.length = length
self.mass = mass
self.gravity = gravity
def forward(self, theta, omega=None):
return -(self.gravity / self.length) * torch.sin(theta)
torch.manual_seed(7)
plt.rcParams['figure.figsize'] = (7, 4)
plt.rcParams['axes.grid'] = True
def to_numpy(x):
if torch.is_tensor(x):
return x.detach().cpu().numpy()
return x
search_root = "./pendulo"
if not os.path.exists(search_root):
os.mkdir(search_root)
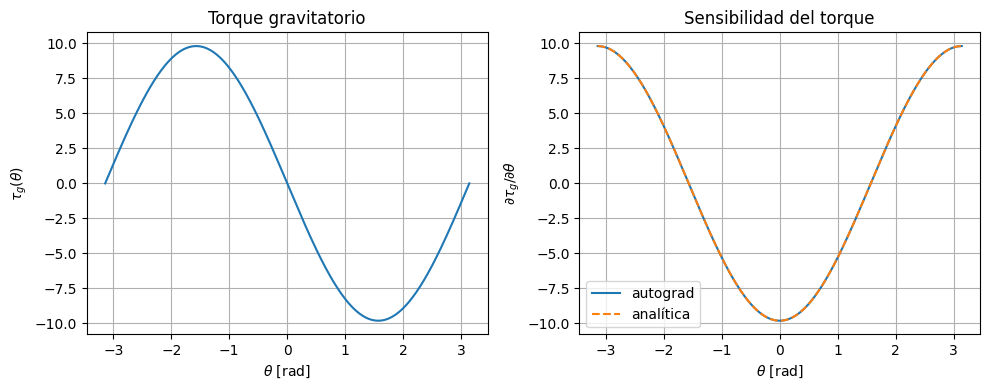
Antes de optimizar una trayectoria completa, conviene inspeccionar el término físico más importante del modelo: el torque gravitatorio. También calculamos su derivada respecto del ángulo para mostrar que incluso esta pieza elemental del sistema ya puede analizarse con autograd.
model = PendulumModel(length=1.0, mass=1.0)
def compute_gradients_vectorized(model, theta, omega):
theta = theta.clone().detach().requires_grad_(True)
omega = omega.clone().detach().requires_grad_(True)
torque = model.forward(theta, omega)
d_torque_d_theta, = grad(torque, theta, grad_outputs=torch.ones_like(torque), create_graph=False)
return d_torque_d_theta
theta_grid = torch.linspace(-torch.pi, torch.pi, 400)
omega_zero = torch.zeros_like(theta_grid)
torque_grid = model.forward(theta_grid, omega_zero)
d_torque_d_theta = compute_gradients_vectorized(model, theta_grid, omega_zero)
d_torque_d_theta_analytic = -(model.gravity / model.length) * torch.cos(theta_grid)
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(to_numpy(theta_grid), to_numpy(torque_grid))
plt.xlabel(r'$\theta$ [rad]')
plt.ylabel(r'$\tau_g(\theta)$')
plt.title('Torque gravitatorio')
plt.subplot(1, 2, 2)
plt.plot(to_numpy(theta_grid), to_numpy(d_torque_d_theta), label='autograd')
plt.plot(to_numpy(theta_grid), to_numpy(d_torque_d_theta_analytic), '--', label='analítica')
plt.xlabel(r'$\theta$ [rad]')
plt.ylabel(r'$\partial \tau_g / \partial \theta$')
plt.title('Sensibilidad del torque')
plt.legend()
plt.tight_layout()
plt.show()
Simulación diferenciable en el tiempo#
Para resolver el problema de control necesitamos pasar de una ecuación diferencial continua a una simulación discreta. Usaremos un esquema de Euler semiimplícito:
No es el integrador más sofisticado, pero alcanza para ilustrar el punto importante: si cada actualización de estado se implementa con operaciones diferenciables, entonces el rollout completo también lo es.
Para esto, procederemos de la siguiente manera:
definir el modelo físico,
integrar su evolución temporal,
medir qué tan cerca queda de la meta,
propagar gradientes hasta los torques de control.
def pendulum_step(model, theta, omega, control_torque, dt, damping=0.05):
gravity_torque = model.forward(theta, omega)
angular_acc = gravity_torque - damping * omega + control_torque / (model.mass * model.length**2)
omega_next = omega + dt * angular_acc
theta_next = theta + dt * omega_next
return theta_next, omega_next
def rollout_pendulum(model, theta0, omega0, controls, dt, damping=0.05):
thetas = [theta0]
omegas = [omega0]
theta, omega = theta0, omega0
for u in controls:
theta, omega = pendulum_step(model, theta, omega, u, dt, damping=damping)
thetas.append(theta)
omegas.append(omega)
return torch.stack(thetas), torch.stack(omegas)
def mechanical_energy(model, thetas, omegas):
kinetic = 0.5 * model.mass * model.length**2 * omegas**2
potential = model.mass * model.gravity * model.length * (1 - torch.cos(thetas))
return kinetic + potential
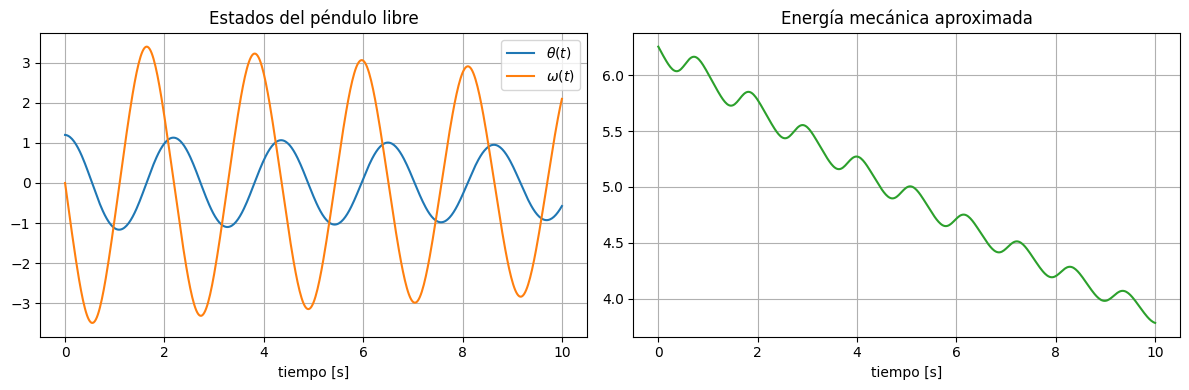
Dinámica sin control#
Primero resolvemos el caso base u_t = 0. Esta simulación libre sirve como referencia física: el péndulo oscila y, por el amortiguamiento, disipa energía con el tiempo.
Tener este comportamiento base es importante porque luego podremos comparar qué cambia cuando la trayectoria ya no surge sólo de la dinámica natural, sino de una optimización sobre el control.
dt = 0.02
steps = 500
controls_zero = torch.zeros(steps)
theta0 = torch.tensor(1.2)
omega0 = torch.tensor(0.0)
thetas_free, omegas_free = rollout_pendulum(model, theta0, omega0, controls_zero, dt)
time = torch.linspace(0.0, steps * dt, steps + 1)
energy_free = mechanical_energy(model, thetas_free, omegas_free)
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
ax[0].plot(to_numpy(time), to_numpy(thetas_free), label=r'$\theta(t)$')
ax[0].plot(to_numpy(time), to_numpy(omegas_free), label=r'$\omega(t)$')
ax[0].set_xlabel('tiempo [s]')
ax[0].set_title('Estados del péndulo libre')
ax[0].legend()
ax[1].plot(to_numpy(time), to_numpy(energy_free), color='tab:green')
ax[1].set_xlabel('tiempo [s]')
ax[1].set_title('Energía mecánica aproximada')
plt.tight_layout()
print(f'Ángulo final libre: {thetas_free[-1].item():.4f} rad')
print(f'Velocidad final libre: {omegas_free[-1].item():.4f} rad/s')
Ángulo final libre: -0.5756 rad
Velocidad final libre: 2.0993 rad/s
Sensibilidades obtenidas con autograd#
Una ventaja clave de la física diferenciable es que permite preguntar cómo cambia un observable final cuando perturbamos el estado inicial. Por ejemplo,
Estas derivadas son relevantes en robótica porque cuantifican sensibilidad, ayudan a estudiar estabilidad local y conectan naturalmente con estimación y diseño de control.
thetas_sens[-1]
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[5], line 1
----> 1 thetas_sens[-1]
NameError: name 'thetas_sens' is not defined
theta0_sens = torch.tensor(1.2, requires_grad=True)
omega0_sens = torch.tensor(0.0, requires_grad=True)
thetas_sens, omegas_sens = rollout_pendulum(model, theta0_sens, omega0_sens, controls_zero, dt)
theta_T = thetas_sens[-1]
print(theta_T)
grad_theta0, grad_omega0 = torch.autograd.grad(theta_T, [theta0_sens, omega0_sens])
print(f'd theta(T) / d theta0 = {grad_theta0.item():.6f}')
print(f'd theta(T) / d omega0 = {grad_omega0.item():.6f}')
tensor(-0.5756, grad_fn=<SelectBackward0>)
d theta(T) / d theta0 = -3.029645
d theta(T) / d omega0 = -0.204996
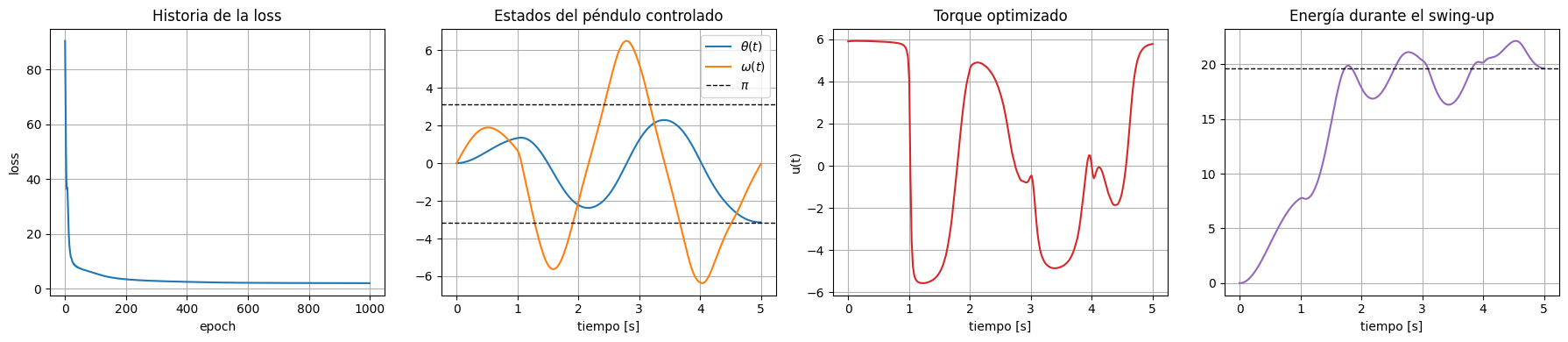
Optimización directa del swing-up#
Ahora formulamos el problema central del notebook: encontrar una secuencia de torques \(u_0, ..., u_{T-1}\) que lleve el péndulo desde reposo hasta la vertical invertida.
La meta angular se expresa de forma periódica, porque \(\theta = \pi\) y \(\theta = -\pi\) representan la misma orientación física. Para evitar discontinuidades, usamos un error angular envuelto:
La función objetivo combina varios términos típicos en control robótico:
error terminal respecto de la postura invertida,
penalización sobre la velocidad final,
cercanía a la energía necesaria para sostener el equilibrio invertido,
regularización del esfuerzo de control y de su suavidad temporal.
Como el simulador es diferenciable, podemos optimizar directamente los torques con Adam sin derivar a mano ecuaciones adjuntas ni linealizar todo el sistema.
def wrap_angle(angle):
return torch.atan2(torch.sin(angle), torch.cos(angle))
def control_loss(model, theta0, omega0, raw_controls, dt, umax=6.0):
controls = umax * torch.tanh(raw_controls)
thetas, omegas = rollout_pendulum(model, theta0, omega0, controls, dt)
energy = mechanical_energy(model, thetas, omegas)
target_energy = 2 * model.mass * model.gravity * model.length
terminal_angle_error = wrap_angle(thetas[-1] - torch.pi)
terminal_loss = 8.0 * terminal_angle_error**2 + 1.5 * omegas[-1]**2
energy_loss = 0.03 * torch.mean((energy - target_energy) ** 2)
effort_loss = 0.0005 * torch.mean(controls**2)
smoothness_loss = 0.01 * torch.mean((controls[1:] - controls[:-1])**2)
total_loss = terminal_loss + energy_loss + effort_loss + smoothness_loss
return total_loss, controls, thetas, omegas, energy
control_horizon = 250
raw_controls = (0.01 * torch.randn(control_horizon)).requires_grad_()
optimizer = torch.optim.Adam([raw_controls], lr=0.05)
loss_history = []
for epoch in range(1000):
optimizer.zero_grad()
loss, controls_opt, thetas_opt, omegas_opt, energy_opt = control_loss(
model,
torch.tensor(0.0),
torch.tensor(0.0),
raw_controls,
dt,
)
loss.backward()
optimizer.step()
loss_history.append(loss.item())
with torch.no_grad():
final_loss, controls_opt, thetas_opt, omegas_opt, energy_opt = control_loss(
model,
torch.tensor(0.0),
torch.tensor(0.0),
raw_controls,
dt,
)
control_time = torch.linspace(0.0, control_horizon * dt, control_horizon)
state_time = torch.linspace(0.0, control_horizon * dt, control_horizon + 1)
fig, ax = plt.subplots(1, 4, figsize=(18, 4))
ax[0].plot(loss_history)
ax[0].set_title('Historia de la loss')
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('loss')
ax[1].plot(to_numpy(state_time), to_numpy(thetas_opt), label=r'$\theta(t)$')
ax[1].plot(to_numpy(state_time), to_numpy(omegas_opt), label=r'$\omega(t)$')
ax[1].axhline(torch.pi, color='black', linestyle='--', linewidth=1, label=r'$\pi$')
ax[1].axhline(-torch.pi, color='black', linestyle='--', linewidth=1)
ax[1].set_title('Estados del péndulo controlado')
ax[1].set_xlabel('tiempo [s]')
ax[1].legend()
ax[2].plot(to_numpy(control_time), to_numpy(controls_opt), color='tab:red')
ax[2].set_title('Torque optimizado')
ax[2].set_xlabel('tiempo [s]')
ax[2].set_ylabel('u(t)')
ax[3].plot(to_numpy(state_time), to_numpy(energy_opt), color='tab:purple')
ax[3].axhline(2 * model.mass * model.gravity * model.length, color='black', linestyle='--', linewidth=1)
ax[3].set_title('Energía durante el swing-up')
ax[3].set_xlabel('tiempo [s]')
plt.tight_layout()
print(f'Loss final: {final_loss.item():.6f}')
print(f'theta final: {thetas_opt[-1].item():.4f} rad')
print(f'omega final: {omegas_opt[-1].item():.4f} rad/s')
print(f'error angular envuelto final: {wrap_angle(thetas_opt[-1] - torch.pi).item():.6f} rad')
Loss final: 1.976107
theta final: -3.1397 rad
omega final: -0.0312 rad/s
error angular envuelto final: 0.001941 rad
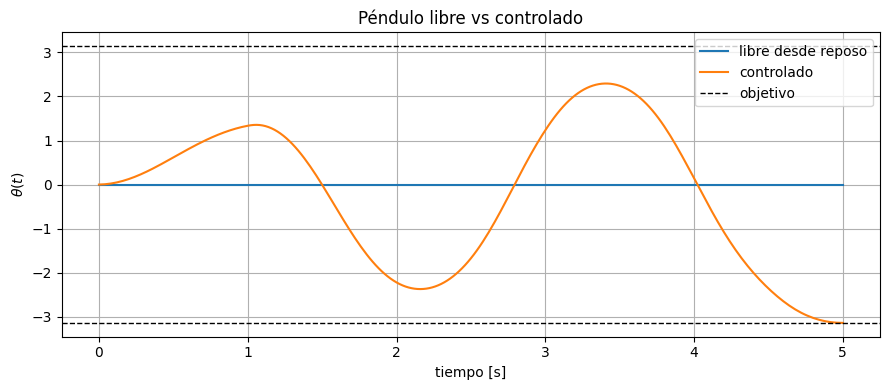
La comparación entre el caso libre y el caso controlado resume el valor del enfoque. Sin control, el sistema sólo sigue su dinámica pasiva y tiende a perder energía. Con control optimizado, la secuencia de torques inyecta y redistribuye energía en los momentos adecuados para acercar el sistema a la postura objetivo.
thetas_rest_free, omegas_rest_free = rollout_pendulum(model, torch.tensor(0.0), torch.tensor(0.0), torch.zeros(control_horizon), dt)
plt.figure(figsize=(9, 4))
plt.plot(to_numpy(state_time), to_numpy(thetas_rest_free), label='libre desde reposo')
plt.plot(to_numpy(state_time), to_numpy(thetas_opt), label='controlado')
plt.axhline(torch.pi, color='black', linestyle='--', linewidth=1, label='objetivo')
plt.axhline(-torch.pi, color='black', linestyle='--', linewidth=1)
plt.xlabel('tiempo [s]')
plt.ylabel(r'$\theta(t)$')
plt.title('Péndulo libre vs controlado')
plt.legend()
plt.tight_layout()
Visualización de la solución#
La animación final no es un detalle cosmético: permite verificar si la trayectoria encontrada tiene sentido físico. En problemas de control y robótica, esta inspección visual ayuda a detectar soluciones numéricas que minimizan la loss pero resultan poco plausibles o poco interpretables.
def pendulum_tip_xy(thetas, length):
x = length * torch.sin(thetas)
y = -length * torch.cos(thetas)
return x, y
x_tip, y_tip = pendulum_tip_xy(thetas_opt, model.length)
gif_path = output_dir / 'pendulo_fd_swingup.gif'
fig, ax = plt.subplots(figsize=(5, 5))
ax.set_xlim(-1.2 * model.length, 1.2 * model.length)
ax.set_ylim(-1.2 * model.length, 1.2 * model.length)
ax.set_aspect('equal')
ax.set_title('Péndulo controlado por física diferenciable')
ax.grid(True)
line, = ax.plot([], [], 'o-', lw=3, color='tab:blue')
trail, = ax.plot([], [], '-', lw=1.2, color='tab:orange', alpha=0.75)
text = ax.text(0.03, 0.95, '', transform=ax.transAxes, va='top')
x_history = []
y_history = []
def init():
line.set_data([], [])
trail.set_data([], [])
text.set_text('')
return line, trail, text
def update(frame):
x = x_tip[frame].item()
y = y_tip[frame].item()
x_history.append(x)
y_history.append(y)
line.set_data([0.0, x], [0.0, y])
trail.set_data(x_history, y_history)
text.set_text(f't = {frame * dt:.2f} s\nθ = {thetas_opt[frame].item():.2f} rad')
return line, trail, text
ani = animation.FuncAnimation(fig, update, frames=len(thetas_opt), init_func=init, interval=40, blit=True)
ani.save(gif_path, writer=animation.PillowWriter(fps=25))
plt.close(fig)
print(f'GIF guardado en: {gif_path}')
display(Image(filename=str(gif_path)))
GIF guardado en: /Users/robledo/repos/apbf_private/codigos/pendulo_fd_swingup.gif
Caída desde la vertical y estabilización activa#
El equilibrio invertido en \(\theta = \pi\) es inestable. En el modelo ideal, si partiéramos exactamente desde \(\theta = \pi\) y \(\omega = 0\), el péndulo permanecería allí por simetría perfecta. Para ver la caída de forma físicamente intuitiva, introducimos una perturbación angular pequeña y dejamos evolucionar el sistema sin torque.
Luego resolvemos el problema complementario: partiendo de esa misma condición inicial, usamos física diferenciable para ajustar los parámetros de un controlador FD que genere los torques necesarios para mantener el péndulo cerca de la vertical durante el mismo intervalo de tiempo.
Por qué aquí conviene optimizar un controlador y no una secuencia abierta de torques#
En el ejemplo de swing-up tenía sentido optimizar directamente \(u_0, \ldots, u_{T-1}\) porque el objetivo era construir una maniobra completa: inyectar energía en momentos precisos y llevar el sistema hasta la vertical al final del horizonte. Ese es un problema naturalmente transitorio.
En cambio, sostener el péndulo cerca de la vertical es un problema de regulación alrededor de un equilibrio inestable. Si optimizáramos sólo una secuencia abierta de torques, esa solución quedaría atada a una trayectoria nominal muy específica: funciona para esa condición inicial y para ese horizonte, pero no corrige desvíos durante la evolución.
Un controlador con realimentación sí usa el estado actual en cada paso. En este caso, el torque depende del error angular respecto de \(\pi\) y de la velocidad angular. Eso permite reaccionar si la gravedad empieza a alejar al péndulo de la vertical, en lugar de seguir aplicando una secuencia prefijada aunque el sistema ya se haya desviado.
La física diferenciable se usa entonces para ajustar automáticamente los parámetros del controlador, no para memorizar una única maniobra. Conceptualmente, pasamos de optimizar una trayectoria abierta a optimizar una ley de control local que estabiliza el equilibrio invertido.
def save_pendulum_gif(thetas, length, dt, gif_path, title):
x_tip, y_tip = pendulum_tip_xy(thetas, length)
fig, ax = plt.subplots(figsize=(5, 5))
ax.set_xlim(-1.2 * length, 1.2 * length)
ax.set_ylim(-1.2 * length, 1.2 * length)
ax.set_aspect('equal')
ax.set_title(title)
ax.grid(True)
line, = ax.plot([], [], 'o-', lw=3, color='tab:blue')
trail, = ax.plot([], [], '-', lw=1.2, color='tab:orange', alpha=0.75)
text = ax.text(0.03, 0.95, '', transform=ax.transAxes, va='top')
x_history = []
y_history = []
def init():
line.set_data([], [])
trail.set_data([], [])
text.set_text('')
return line, trail, text
def update(frame):
x = x_tip[frame].item()
y = y_tip[frame].item()
x_history.append(x)
y_history.append(y)
line.set_data([0.0, x], [0.0, y])
trail.set_data(x_history, y_history)
text.set_text(f't = {frame * dt:.2f} s\nθ = {thetas[frame].item():.2f} rad')
return line, trail, text
ani = animation.FuncAnimation(fig, update, frames=len(thetas), init_func=init, interval=40, blit=True)
ani.save(gif_path, writer=animation.PillowWriter(fps=25))
plt.close(fig)
def rollout_with_pd(model, theta0, omega0, gains, dt, steps, damping=0.05, umax=10.0):
'''proporcional derivativo'''
# proporcional
kp = torch.nn.functional.softplus(gains[0])
# derivativo
kd = torch.nn.functional.softplus(gains[1])
thetas = [theta0]
omegas = [omega0]
controls = []
theta, omega = theta0, omega0
for _ in range(steps):
angle_error = wrap_angle(theta - torch.pi)
# ley de control
control_torque = umax * torch.tanh(-kp * angle_error - kd * omega)
theta, omega = pendulum_step(model, theta, omega, control_torque, dt, damping=damping)
controls.append(control_torque)
thetas.append(theta)
omegas.append(omega)
return torch.stack(controls), torch.stack(thetas), torch.stack(omegas), kp, kd
def upright_pd_loss(model, theta0, omega0, gains, dt, steps, damping=0.05, umax=10.0):
controls, thetas, omegas, kp, kd = rollout_with_pd(
model, theta0, omega0, gains, dt, steps, damping=damping, umax=umax
)
upright_error = wrap_angle(thetas - torch.pi)
tracking_loss = 40.0 * torch.mean(upright_error**2)
velocity_loss = 4.0 * torch.mean(omegas**2)
terminal_loss = 20.0 * upright_error[-1]**2 + 3.0 * omegas[-1]**2
effort_loss = 0.002 * torch.mean(controls**2)
smoothness_loss = 0.01 * torch.mean((controls[1:] - controls[:-1])**2)
total_loss = tracking_loss + velocity_loss + terminal_loss + effort_loss + smoothness_loss
return total_loss, controls, thetas, omegas, upright_error, kp, kd
upright_steps = control_horizon
theta0_upright = torch.tensor(torch.pi - 0.5)
omega0_upright = torch.tensor(0.0)
controls_zero_upright = torch.zeros(upright_steps)
upright_time = torch.linspace(0.0, upright_steps * dt, upright_steps + 1)
control_time_upright = torch.linspace(0.0, upright_steps * dt, upright_steps)
thetas_fall, omegas_fall = rollout_pendulum(
model, theta0_upright, omega0_upright, controls_zero_upright, dt
)
fall_gif_path = output_dir / 'pendulo_fd_caida_desde_vertical.gif'
save_pendulum_gif(
thetas_fall,
model.length,
dt,
fall_gif_path,
'Caída libre desde la vertical perturbada',
)
print(f'GIF de caída libre guardado en: {fall_gif_path}')
display(Image(filename=str(fall_gif_path)))
pd_gains = torch.zeros(2, requires_grad=True)
optimizer_pd = torch.optim.Adam([pd_gains], lr=0.05)
upright_loss_history = []
for epoch in range(1000):
optimizer_pd.zero_grad()
loss, controls_hold, thetas_hold, omegas_hold, upright_error, kp_opt, kd_opt = upright_pd_loss(
model, theta0_upright, omega0_upright, pd_gains, dt, upright_steps
)
loss.backward()
optimizer_pd.step()
upright_loss_history.append(loss.item())
with torch.no_grad():
final_hold_loss, controls_hold, thetas_hold, omegas_hold, upright_error, kp_opt, kd_opt = upright_pd_loss(
model, theta0_upright, omega0_upright, pd_gains, dt, upright_steps
)
hold_gif_path = output_dir / 'pendulo_fd_estabilizacion_vertical.gif'
save_pendulum_gif(
thetas_hold,
model.length,
dt,
hold_gif_path,
'Péndulo estabilizado cerca de la vertical',
)
print(f'GIF de estabilización guardado en: {hold_gif_path}')
display(Image(filename=str(hold_gif_path)))
fig, ax = plt.subplots(1, 4, figsize=(18, 4))
ax[0].plot(upright_loss_history)
ax[0].set_title('Historia de la loss de estabilización')
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('loss')
ax[1].plot(to_numpy(upright_time), to_numpy(thetas_fall), label='sin torque')
ax[1].plot(to_numpy(upright_time), to_numpy(thetas_hold), label='con control PD optimizado')
ax[1].axhline(torch.pi, color='black', linestyle='--', linewidth=1, label=r'$\pi$')
ax[1].axhline(0.0, color='tab:gray', linestyle=':', linewidth=1, label='posición colgante')
ax[1].set_title('Ángulo desde la vertical perturbada')
ax[1].set_xlabel('tiempo [s]')
ax[1].legend()
ax[2].plot(to_numpy(control_time_upright), to_numpy(controls_hold), color='tab:red')
ax[2].set_title('Torque de estabilización')
ax[2].set_xlabel('tiempo [s]')
ax[2].set_ylabel('u(t)')
ax[3].plot(to_numpy(upright_time), to_numpy(upright_error), color='tab:green')
ax[3].axhline(0.0, color='black', linestyle='--', linewidth=1)
ax[3].set_title('Error angular respecto de la vertical')
ax[3].set_xlabel('tiempo [s]')
ax[3].set_ylabel(r'wrap($\theta - \pi$)')
plt.tight_layout()
print(f'kp optimizado: {kp_opt.item():.4f}')
print(f'kd optimizado: {kd_opt.item():.4f}')
print(f'loss final de estabilización: {final_hold_loss.item():.6f}')
print(f'error angular máximo con control: {torch.max(torch.abs(upright_error)).item():.6f} rad')
print(f'torque máximo aplicado: {torch.max(torch.abs(controls_hold)).item():.6f}')
GIF de caída libre guardado en: /Users/robledo/repos/apbf_private/codigos/pendulo_fd_caida_desde_vertical.gif
GIF de estabilización guardado en: /Users/robledo/repos/apbf_private/codigos/pendulo_fd_estabilizacion_vertical.gif
kp optimizado: 1.9796
kd optimizado: 0.4350
loss final de estabilización: 0.988607
error angular máximo con control: 0.500000 rad
torque máximo aplicado: 7.572694
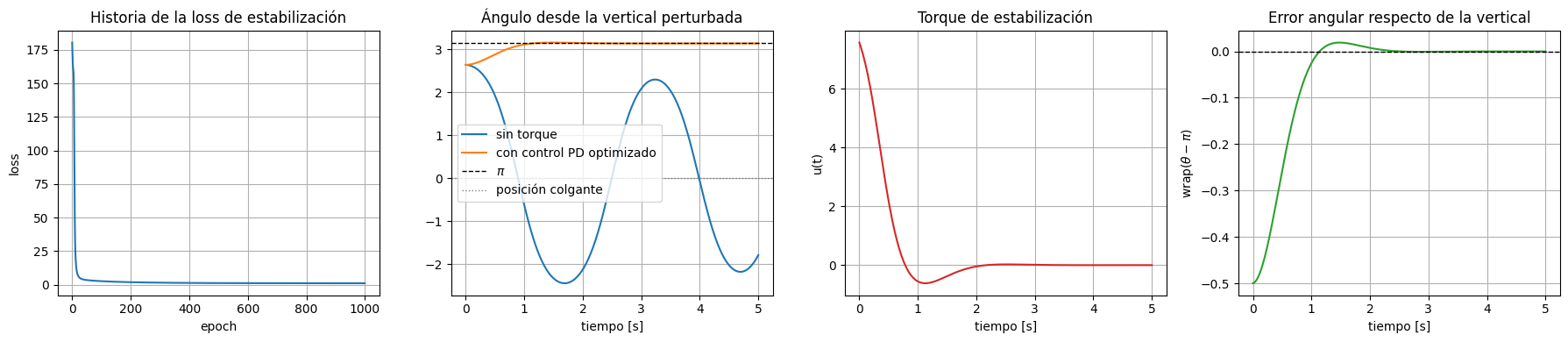
En este experimento aparecen dos ideas complementarias. Sin control, la vertical invertida no se sostiene: una perturbación pequeña basta para que la gravedad aleje al sistema y termine cayendo hacia la configuración colgante. Con control, en cambio, la física diferenciable se usa para ajustar automáticamente un regulador PD cuyos torques contrarrestan esa inestabilidad.
La diferencia con el swing-up anterior es conceptual: antes el objetivo era inyectar energía para alcanzar la vertical; aquí el objetivo es regular alrededor de un equilibrio inestable y mantener la trayectoria cerca de \(\theta = \pi\) durante todo el horizonte.
Física diferenciable + red neuronal como controlador#
Una extensión natural del enfoque es reemplazar el controlador diseñado a mano por una red neuronal. La idea es que la red reciba el estado actual del péndulo y produzca el torque de control, mientras que el simulador diferenciable se encarga de propagar la trayectoria y devolver gradientes hacia los pesos de la red.
En esta sección usamos una política neuronal pequeña que observa sin(theta), cos(theta) y omega. La representación trigonométrica evita la discontinuidad angular entre \(\pi\) y \(-\pi\). Luego entrenamos esa política para resolver nuevamente el swing-up, pero ahora optimizando parámetros de una NN en lugar de una secuencia fija de torques.
class NeuralPolicy(torch.nn.Module):
def __init__(self, hidden_dim=32):
super().__init__()
self.net = torch.nn.Sequential(
torch.nn.Linear(3, hidden_dim),
torch.nn.Tanh(),
torch.nn.Linear(hidden_dim, hidden_dim),
torch.nn.Tanh(),
torch.nn.Linear(hidden_dim, 1),
)
def forward(self, theta, omega, umax=8.0):
state = torch.stack([
torch.sin(theta),
torch.cos(theta),
omega,
], dim=-1)
raw_control = self.net(state).squeeze(-1)
return umax * torch.tanh(raw_control)
def rollout_with_nn_policy(model, policy, theta0, omega0, steps, dt, damping=0.05, umax=8.0):
thetas = [theta0]
omegas = [omega0]
controls = []
theta, omega = theta0, omega0
for _ in range(steps):
control_torque = policy(theta, omega, umax=umax)
theta, omega = pendulum_step(model, theta, omega, control_torque, dt, damping=damping)
thetas.append(theta)
omegas.append(omega)
controls.append(control_torque)
return torch.stack(thetas), torch.stack(omegas), torch.stack(controls)
def nn_swingup_loss(model, policy, theta0, omega0, steps, dt, damping=0.05, umax=8.0):
thetas, omegas, controls = rollout_with_nn_policy(
model, policy, theta0, omega0, steps, dt, damping=damping, umax=umax
)
energy = mechanical_energy(model, thetas, omegas)
target_energy = 2 * model.mass * model.gravity * model.length
terminal_angle_error = wrap_angle(thetas[-1] - torch.pi)
terminal_loss = 12.0 * terminal_angle_error**2 + 2.0 * omegas[-1]**2
energy_loss = 0.02 * torch.mean((energy - target_energy) ** 2)
effort_loss = 0.0005 * torch.mean(controls**2)
smoothness_loss = 0.01 * torch.mean((controls[1:] - controls[:-1])**2)
total_loss = terminal_loss + energy_loss + effort_loss + smoothness_loss
return total_loss, thetas, omegas, controls, energy
torch.manual_seed(7)
nn_policy = NeuralPolicy(hidden_dim=32)
optimizer_nn = torch.optim.Adam(nn_policy.parameters(), lr=2e-3)
nn_loss_history = []
for epoch in range(1200):
optimizer_nn.zero_grad()
nn_loss, thetas_nn, omegas_nn, controls_nn, energy_nn = nn_swingup_loss(
model,
nn_policy,
torch.tensor(0.0),
torch.tensor(0.0),
control_horizon,
dt,
)
nn_loss.backward()
optimizer_nn.step()
nn_loss_history.append(nn_loss.item())
with torch.no_grad():
final_nn_loss, thetas_nn, omegas_nn, controls_nn, energy_nn = nn_swingup_loss(
model,
nn_policy,
torch.tensor(0.0),
torch.tensor(0.0),
control_horizon,
dt,
)
nn_gif_path = output_dir / 'pendulo_fd_nn_controller.gif'
save_pendulum_gif(
thetas_nn,
model.length,
dt,
nn_gif_path,
'Swing-up con política neuronal entrenada con FD',
)
print(f'GIF de control neuronal guardado en: {nn_gif_path}')
display(Image(filename=str(nn_gif_path)))
fig, ax = plt.subplots(1, 4, figsize=(18, 4))
ax[0].plot(nn_loss_history)
ax[0].set_title('Historia de la loss de la NN')
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('loss')
ax[1].plot(to_numpy(state_time), to_numpy(thetas_opt), label='torques abiertos optimizados')
ax[1].plot(to_numpy(state_time), to_numpy(thetas_nn), label='política neuronal')
ax[1].axhline(torch.pi, color='black', linestyle='--', linewidth=1, label=r'$\pi$')
ax[1].axhline(-torch.pi, color='black', linestyle='--', linewidth=1)
ax[1].set_title('Swing-up: abierto vs NN')
ax[1].set_xlabel('tiempo [s]')
ax[1].legend()
ax[2].plot(to_numpy(control_time), to_numpy(controls_nn), color='tab:red')
ax[2].set_title('Torque generado por la NN')
ax[2].set_xlabel('tiempo [s]')
ax[2].set_ylabel('u(t)')
ax[3].plot(to_numpy(state_time), to_numpy(energy_nn), color='tab:purple')
ax[3].axhline(2 * model.mass * model.gravity * model.length, color='black', linestyle='--', linewidth=1)
ax[3].set_title('Energía con controlador neuronal')
ax[3].set_xlabel('tiempo [s]')
plt.tight_layout()
print(f'Loss final NN: {final_nn_loss.item():.6f}')
print(f'theta final NN: {thetas_nn[-1].item():.4f} rad')
print(f'omega final NN: {omegas_nn[-1].item():.4f} rad/s')
print(f'error angular envuelto final NN: {wrap_angle(thetas_nn[-1] - torch.pi).item():.6f} rad')
print(f'torque máximo NN: {torch.max(torch.abs(controls_nn)).item():.6f}')
GIF de control neuronal guardado en: /Users/robledo/repos/apbf_private/codigos/pendulo_fd_nn_controller.gif
Loss final NN: 2.640390
theta final NN: 3.0299 rad
omega final NN: -0.0602 rad/s
error angular envuelto final NN: -0.111727 rad
torque máximo NN: 7.295632
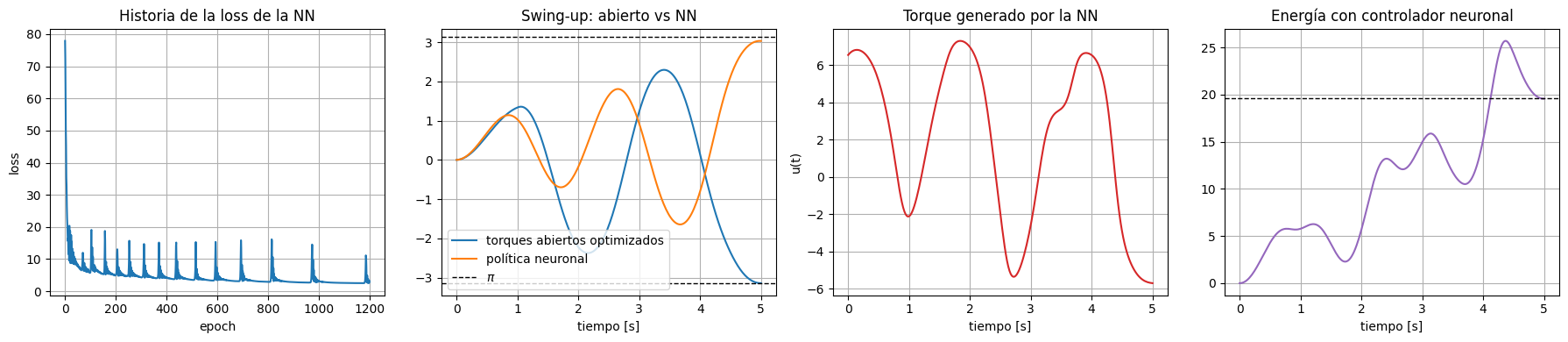
Este experimento muestra una combinación más general de FD + aprendizaje. En lugar de optimizar directamente los torques de una sola trayectoria, optimizamos los pesos de una política que decide el torque a partir del estado instantáneo del sistema. El simulador diferenciable actúa como puente entre la decisión de la red y el resultado físico de largo plazo.
La ventaja conceptual es que la red aprende una ley de control, no sólo una maniobra puntual.