8.7. Introducción a PyTorch#
![]()
8.7.1. Parte 1: Tensores#
Un tensor es un objeto matemático que generaliza conceptos como escalares, vectores y matrices para representar relaciones entre múltiples direcciones en un espacio.
En Aprendizaje automático profundo, lo vamos a utilizar como sinónimo de array multidimensional.
El escalar es un tensor de orden 0, un vector es un tensor de orden 1, una matriz uno de orden 2, y podemos generalizarlo para un tensor de orden n.
Un tensor tiene componentes y transforma de manera especifica. En PyTorch, existen muchas maneras diferentes de crear tensores y un conjunto amplio de métodos y funciones para operar con ellos. Algunas funciones para generar tensores:
import torch
# Desde lista
a = torch.tensor([1, 2, 3])
# Ceros / unos
b = torch.zeros(2, 3)
c = torch.ones(2, 3)
# Aleatorio
d = torch.rand(2, 3)
# Rango
e = torch.arange(0, 10)
Propiedades básicas de los tensores en PyTorch#
# imprimir tamaño, tipo de dato y dispositivo
print(a.shape) # tamaño
print(a.dtype) # tipo de dato
print(a.device) # CPU o GPU
torch.Size([3])
torch.int64
cpu
Operaciones básicas#
Podemos hacer aritmética elemento a elemento entre tensores:
x = torch.tensor([1.0, 2.0, 3.0])
y = torch.tensor([4.0, 5.0, 6.0])
# hacer x + y, x - y, x * y, x / y
print(x + y) # suma
print(x - y) # resta
print(x * y) # multiplicación
print(x / y) # división
tensor([5., 7., 9.])
tensor([-3., -3., -3.])
tensor([ 4., 10., 18.])
tensor([0.2500, 0.4000, 0.5000])
También permite directamente la operación con escalares de manera intuitiva y sencilla
x * 2
tensor([2., 4., 6.])
y + 10
tensor([14., 15., 16.])
Una operación muy importante y utilizada en PyTorch es el broadcasting en donde se expanden dimensiones de tensores para poder operar con ellos automáticamente (siempre tener cuidado con esto)
x = torch.randint(0, 10, (2, 3))
print('x:', x)
print('x.shape:', x.shape)
y = torch.randint(0, 10, (3,))
print('y:', y)
print('y.shape:', y.shape)
z = x + y # y se “expande”
print(z)
x: tensor([[2, 7, 8],
[5, 5, 1]])
x.shape: torch.Size([2, 3])
y: tensor([6, 2, 4])
y.shape: torch.Size([3])
tensor([[ 8, 9, 12],
[11, 7, 5]])
El broadcasting sucede para todas las operaciones básicas.
También podemos elegir elementos de tensores mediante índices, lo que se conoce como slicing
x = torch.tensor([[1, 2, 3, 5],
[4, 5, 6, 7]])
print(x[0, 1]) # 2
print(x[:, 1]) # columna
print(x[1, :]) # fila
print(x[1, 0:2]) # elementos 0 y 1 de la fila 1
print(x[1,0::2]) # elementos 0 y 2 de la fila 1
tensor(2)
tensor([2, 5])
tensor([4, 5, 6, 7])
tensor([4, 5])
tensor([4, 6])
Cuando tratamos con multiplicaciones matriciales, existe tanto función como operación básica que permite realizar la operación:
A = torch.rand(2, 3)
B = torch.rand(3, 4)
C = torch.matmul(A, B)
C_bis = A @ B
print(C)
print(C_bis)
print(torch.allclose(C, C_bis))
tensor([[1.2335, 1.3969, 1.1392, 1.8715],
[1.0250, 1.4183, 1.1348, 1.4496]])
tensor([[1.2335, 1.3969, 1.1392, 1.8715],
[1.0250, 1.4183, 1.1348, 1.4496]])
True
También podemos obtener la transpuesta de una matriz fácilmente con
A.T
tensor([[0.2911, 0.9550],
[0.8669, 0.4962],
[0.9633, 0.1489]])
Métodos implícitos en tensores muy útiles#
Los tensores de PyTorch también tienen métodos inherentes que permiten operaciones sencillas muy utilizadas, como la suma de las componentes, el valor medio, máximo, mínimo, desvío estándar, etc. Estas operaciones se pueden hacer para todo el tensor o para algunas componentes del mismo, seleccionando la dimensión sobre la cuál se desea hacer.
x = torch.rand(2, 3)
print(x)
print('suma', x.sum())
print('media', x.mean())
print('máximo', x.max())
print('mínimo', x.min())
print('desviación estándar', x.std())
# por dimensión
print('suma por columnas', x.sum(dim=0))
print('media por filas', x.mean(dim=1))
tensor([[0.2407, 0.7426, 0.2729],
[0.7252, 0.7869, 0.3378]])
suma tensor(3.1060)
media tensor(0.5177)
máximo tensor(0.7869)
mínimo tensor(0.2407)
desviación estándar tensor(0.2589)
suma por columnas tensor([0.9659, 1.5295, 0.6107])
media por filas tensor([0.4187, 0.6166])
Cambiar forma#
A veces es necesario ver a los datos en distintas representaciones tensoriales.
x = torch.arange(6)
x = x.reshape(2, 3)
print(x)
tensor([[0, 1, 2],
[3, 4, 5]])
x.view(3,2)
tensor([[0, 1],
[2, 3],
[4, 5]])
Concatenación#
Los tensores se pueden unir de maneras específicas para representarlos en un tensor de mayor dimensión
a = torch.rand(2, 3)
b = torch.rand(2, 3)
print('concatenación por filas \n', torch.cat([a, b], dim=0))
print('concatenación por columnas \n', torch.cat([a, b], dim=1))
concatenación por filas
tensor([[0.7089, 0.8001, 0.4241],
[0.2969, 0.1895, 0.7835],
[0.4591, 0.4791, 0.7974],
[0.4516, 0.8575, 0.8836]])
concatenación por columnas
tensor([[0.7089, 0.8001, 0.4241, 0.4591, 0.4791, 0.7974],
[0.2969, 0.1895, 0.7835, 0.4516, 0.8575, 0.8836]])
Esto también se puede lograr con hstack y vstack
print('concatenación por filas \n', torch.vstack([a, b])) # filas
print('concatenación por columnas \n', torch.hstack([a, b])) # columnas
concatenación por filas
tensor([[0.7089, 0.8001, 0.4241],
[0.2969, 0.1895, 0.7835],
[0.4591, 0.4791, 0.7974],
[0.4516, 0.8575, 0.8836]])
concatenación por columnas
tensor([[0.7089, 0.8001, 0.4241, 0.4591, 0.4791, 0.7974],
[0.2969, 0.1895, 0.7835, 0.4516, 0.8575, 0.8836]])
Cambio de dispostivo dónde realizar los cómputos#
Si queremos trabajar con los procesadores de la GPU, todo tensor involucrado en la operación debe estar previamente en la GPU. PyTorch ofrece el método .to() para mover tensores de la CPU a la GPU de manera sencilla.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x = torch.rand(3, 3).to(device)
print(x.device)
cpu
import time
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Usando:", device)
Usando: cpu
N = 3000
A_cpu = torch.rand(N, N)
B_cpu = torch.rand(N, N)
# ---- CPU timing ----
start = time.perf_counter()
C_cpu = A_cpu @ B_cpu
end = time.perf_counter()
cpu_time = end - start
print(f"CPU time: {cpu_time:.4f} seconds")
if torch.cuda.is_available():
# ---- GPU timing ----
A_gpu = A_cpu.to(device)
B_gpu = B_cpu.to(device)
# Warm-up: evita medir la sobrecarga de la primera operación en GPU
_ = A_gpu @ B_gpu
torch.cuda.synchronize()
start = time.perf_counter()
C_gpu = A_gpu @ B_gpu
torch.cuda.synchronize()
end = time.perf_counter()
gpu_time = end - start
print(f"GPU time: {gpu_time:.4f} seconds")
print(f"Speedup: {cpu_time / gpu_time:.2f}x")
else:
print("GPU no disponible, solo se midió el tiempo en CPU.")
CPU time: 0.0648 seconds
GPU no disponible, solo se midió el tiempo en CPU.
Expandir o aplastar tensores#
A veces necesitamos una dimensión de más o una de menos. Esto se puede modificar con los métodos .squeeze() y unsqueeze(). Cuando hacemos unsqueeze, hay que indicarle en qué posición del tensor vamos a agregar una nueva dimensión. Cuando hacemos squeeze, sólo comprime aquellas dimensiones que tenga una sola componente o bien la componente indicada.
x = torch.tensor([1.0, 2.0, 3.0])
x_expandido = x.unsqueeze(0) # añade dimensión al inicio
print(x_expandido.shape)
print(x_expandido.unsqueeze(2).shape)
print(x_expandido.shape)
print(x_expandido.squeeze().shape)
torch.Size([1, 3])
torch.Size([1, 3, 1])
torch.Size([1, 3])
torch.Size([3])
8.7.2. Grafos computacionales dinámicos: gráfos acíclicos direccionados#
En PyTorch, podemos definir que un tensor mantenga información de cómo cambia el resultado final de una operación que lo involucra, con respecto a sigo mismo. Para ello almacenamos junto al tensor, su gradiente calculado. Esto se puede hacer de la siguiente manera:
x = torch.tensor([3.0], requires_grad=True)
y = x**2
z = 7*y
Luego de esta operación, como requires_grad=True, PyTorch construye un grafo acíclico direccionado, que mantiene la relación
donde en cada operación se guarda como se calculó y como derivar respecto a la variable, siguiendo al regla de la cadena.
#dy/dx = 2x, si x=3, dy/dx = 6
y.backward(retain_graph=True) #dy/dx se almacena en x.grad
print(x.grad)
tensor([6.])
Recordar resetear el gradiente en el medio, sino se acumulan los valores
x.grad.zero_()
z.backward() #dz/dx = dz/dy * dy/dx = 7 * 2*3 = 42
print(x.grad)
tensor([42.])
Veamos un ejemplo cuando tenemos más que un escalar, en este caso ya se trabaja con el gradiente como vector
x = torch.tensor([ 3.0, 2.0], requires_grad=True)
y = x * 2
z = y.sum()
z.backward()
print(x.grad)
tensor([2., 2.])
Lo mismo si tenemos distintas variables
# Creat tensores
x = torch.tensor(2.0, requires_grad=True)
y = torch.tensor(3.0, requires_grad=True)
# realizar una operación
z = x * y + y ** 2
# retropropagación
z.backward()
# Gradientes
def mostrar_gradientes():
print(f'dz/dx: {x.grad}') # Output: 3.0
print(f'dz/dy: {y.grad}') # Output: 8.0
mostrar_gradientes()
dz/dx: 3.0
dz/dy: 8.0
En este ejemplo, PyTorch construye un gráfico dinámico a medida que se van ejecutando las operaciones. la función backward() computa los gradientes automáticamente utilizando el grafo. Una vez que se utilizó para computar el gradiente, el grafo es eliminado de la memoria, a menos que se explicite lo contrario.
8.7.3. Parte 2: Loop de entrenamiento en PyTorch#
En esta parte vamos a ver el loop de entrenamiento completo en PyTorch que utilizaremos a lo largo de la materia.
Datos#
Por un lado necesitaremos un conjunto de datos (sean sintéticos para que sean ilustrativos o una base de datos real) de la cuál podamos aprender. Todos los modelos que veremos son centrados en los datos (data-centric), pero veremos más adelante cómo hacer para incluir conocimiento de los sitemas bajo estudio en el aprendizaje. Sin embargo, seguiremos siempre aprendiendo y pesando fuertemente la componente de ajuste a los datos observados.
En este caso, generaremos datos utilizando una funcion_compleja que presenta un comportamiento suficientemente complejo como para ajustarlo con modelos lineales o no lineales sencillos de pocos parámetros.
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
import matplotlib.pyplot as plt
# ===========================================================
# 1. Generación de datos
# ===========================================================
def funcion_compleja(x):
return (
np.abs(x) ** 0.5
+ 0.1 * x
+ 0.01 * x**2
+ 1
- np.sin(x)
+ 0.5 * np.exp(x / 10.0)
) / (0.5 + np.abs(np.cos(x)))
N = 1_000
xdata = np.linspace(-10, 10, N).reshape(-1, 1).astype(np.float32)
ydata = funcion_compleja(xdata).astype(np.float32)
plt.figure(figsize=(10, 6))
plt.scatter(xdata, ydata, color="black", label="Datos reales", s=1)
plt.xlabel("x")
plt.ylabel("funcion_compleja(x)")
plt.title("Datos de entrenamiento")
plt.legend()
plt.grid(True)
# Pasamos a tensores de PyTorch
X = torch.from_numpy(xdata)
Y = torch.from_numpy(ydata)
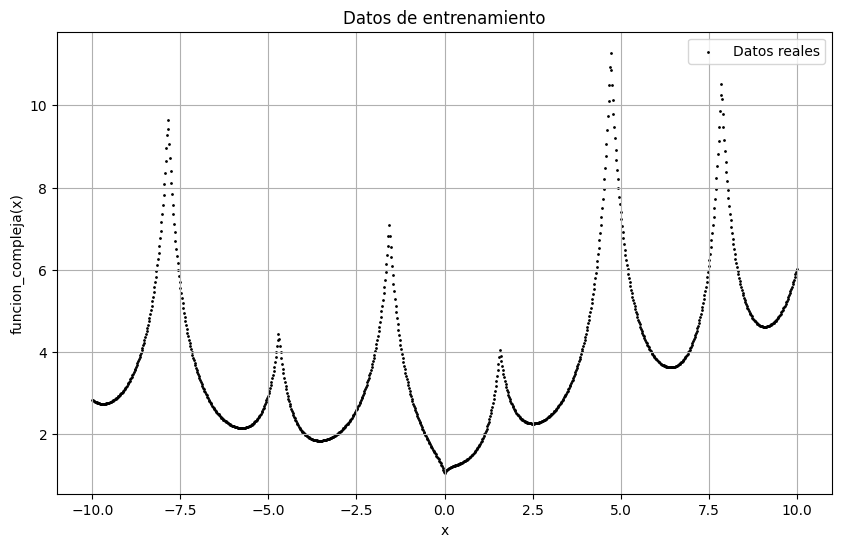
una vez obtenido el conjunto de datos, nos preguntamos qué tipo de problema queremos resolver. En este caso, podríamos entrenar una red neuronal tipo perceptrón multicapa que aprenda los datos \(y\) en función de \(x\), es decir un problema de regresión de una variable. En este caso vamos a poner a prueba el teorema de aproximación universal, que establece que, dada una función \(f\) continua, existe una red neuronal del tipo MLP de 1 capa tal que puede aproximar. Ojo, el teorema no dice cuál es la red ni cuántas neuronas harán falta, sino que establece la existencia. Podemos probar con distintas arquitecturas de MLP y de paso aprender como fuciona loop de entrenamiento de un modelo en PyTorch.
A continuación, muestro dos maneras en las que se pueden particionar los datos en conjuntos de entrenamiento y de prueba. Esto es un procedimiento usual en el aprendizaje automático, ya que es necesario probar los modelos en datos que no fueron utilizados para entrenarlo. En realidad, se estila separar al conjunto de datos en 3 conjuntos: uno de entrenamiento, otro de validación, y uno final de prueba. El de entrenamiento se utiliza para entrenar el modelo, es decir actualizar los parámetros del mismo con tal de minimizar la función de costo. El de validación se suele utilizar dentro del loop de entrenamiento, para tomar decisiones también, como elegir hiperparámetros del modelo, hacerlo early-stopping, o inclusive comparar modelos. En este caso, no entrenamos a los modelos con estos datos, pero decidimos cuál modelo utilizar en base a cómo se comportan frente a estos datos. Finalmente, se utiliza el conjunto de prueba para poner a prueba el modelo final elegido ante datos nunca antes visto.
from torch.utils.data import random_split
dataset = TensorDataset(X, Y)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, val_dataset, test_dataset = random_split(dataset=dataset,
lengths=[train_size, int(test_size*0.8), int(test_size*0.2)],
generator=torch.Generator().manual_seed(42))
DataLoader y batches#
Contamos con una base de datos que tienen 1000 puntos. Para entrenar, podríamos pasar todos los datos por el modelo. Esto se llama una época. Luego, podríamos calcular la función de costo considerando todos los resultados obtenidos en la época, luego hacer la retropropagación y obtener una estimación del gradiente para el conjunto de parámetros \(w\) de la red y tomar la decisión de cómo actualizarlos como hemos visto en al teoría. Esto se llama descenso por el gradiente y puede resultar muy costoso y lento, ya que para realizar una actualización en el espacio de los parámetros de la red, debemos ver a todos los datos de la época! Otra opción es hacer un descenso estocástico por el gradiente, que implica actualizar el gradiente luego de ver cada punto del conjunto de datos de entrenamiento. Esto es mucho más rápido, pero la aproximación al gradiente en el el punto del espacio de parámetros en donde estamos a partir de un sólo dato puede ser demasiado burda y por lo tanto introducir demasiado ruido a la optimización. El concepto de mini-batch es un punto intermedio y consiste en pensar que podemos aproximar al gradiente con menos cantidad de puntos que el conjunto total de datos, pero más que 1 solo dato, y que esa estimación es mejor y suficiente como para encontrar una actualización razonable de los pesos. De esta manera, podríamos realizar varias actualizaciones de pesos por época, y así converger más rápido, con gradientes relativamente bien estimados.
DataLoader en PyTorch es la herramienta que se encarga de entregar los datos al modelo durante el entrenamiento de forma eficiente y organizada. DataLoader toma un Dataset de PyTorch y lo convierte en un iterador de batches, con tamaño de batch determinado en batch_size. También se encarga de mezclar los datos si shuffle=True. También es capaz de utilizar múltiples procesos para cargar los datos, lo que acelera el entrenamiento con grandes bases de datos.
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
Definición de modelo#
Ahora podemos proceder a armar un perceptrón multicapa utilizando PyTorch. Para armar un modelo que luego tenga el comportamiento esperado por el paquete, debemos heredar de nn.Module. Entre las funcionalidades heredadas se encuentra el hecho que cuando llamamos modelo(x), se haga un pase del método llamado forward de la clase, evaluada en los datos \(x\).
Debemos siempre comenzar la clase definiendo el método de inicialización que debe llevar de nombre __init__. El argumento self hace referencia a la clase misma, y es lo que permita que sea llamado desde dentro de la instancia y que encuentre los demás métodos y atributos de la clase. No olvidarse que los métodos deben entonces autoreferenciarse con la palabra self. Luego, siguen los argumentos que se le pasaran como constructor a la instancia. Estos serían los parámetros inicializadores del modelo. Cualquier argumento que tenga un valor por default será opcional y se le asignará el valor default si no se menciona en la inicialización de la instancia. Aquellos sin valor por default son obligatorios a la hora de instanciar la clase.
La línea super().__init__() ejecuta el método de inicialización de la clase de la cuál se hereda (en este caso nn.Module). Luego definimos la arquitectura de nuestro modelo, En este caso, vamos agregando capas Lineales al modelo intercaladas con funciones de activación ReLU. Estas son agregadas a una lista que luego es son pasadas a nn.Sequential. Esta clase interpreta el orden de las capas y aplica de manera secuencial las capas a los datos de entrada. La red se guarda dentro de un atributo llamado self.net. Fijarse que, a continuación, se define el método forward que los módulos nn.Module esperan para llamar a la red y evaluarla en los datos \(x\) que sean pasados de entrada.
Esta clase, que llamamos MLP1D, define la arquitectura de nuestro modelo perceptrón multicapa, en donde al fin y al cabo se está planteando una red neuronal que recibe input_dim entradas, genera nb_layers capas ocultas con función de activación ReLU, con nb_nodes nodos en el medio, y luego compagina el resultado en una salida.
Muestro a continuación una instanciación de la clase para una única capa con 200 neuronas. Además defino un entrenamiento de 4000 épocas
class MLP1D(nn.Module):
def __init__(self, input_dim, nb_layers=3, nb_nodes=20):
super().__init__()
layers = []
layers.append(nn.Linear(input_dim, nb_nodes))
layers.append(nn.ReLU())
for _ in range(nb_layers - 1):
layers.append(nn.Linear(nb_nodes, nb_nodes))
layers.append(nn.ReLU())
layers.append(nn.Linear(nb_nodes, 1))
self.net = nn.Sequential(*layers)
def forward(self, x):
return self.net(x)
nb_layers = 1
nb_nodes = 200
epochs = 4_000
save_period = 400
saved_epochs = list(range(save_period, epochs + 1, save_period))
model = MLP1D(input_dim=X.shape[1], nb_layers=nb_layers, nb_nodes=nb_nodes)
print(model)
MLP1D(
(net): Sequential(
(0): Linear(in_features=1, out_features=200, bias=True)
(1): ReLU()
(2): Linear(in_features=200, out_features=1, bias=True)
)
)
Definición de función de costo y optimizador#
Una vez definido el modelo y los datos, debemos pensar cuál es el criterio que vamos a utilizar para optimizar, es decir qué función de costo corresponde al problema de interés. Como estamos pensando en un problema de regresión, podemos plantear cualquiera de las mencionadas en el teórico. Entre ellas, podemos plantear la pérdida de Huber como ejemplo (pueden probar con otras). Para esto utilizamos la clase de pytorch nn.HuberLoss.
Además, nos resta definir como vamos a realizar la optimización, es decir cuál algoritmo de optimización queremos utilizar. En este caso, probaremos con RMSprop, pero siéntanse libres de probar con otros también. Es importante notar que debemos especificar cuáles son los parámetros optimizables del modelo. En este caso, queremos optimizar todos los parámetros del modelo que instanciamos que se definen por default como entrenables en las capas de pytorch utilizadas, y por ende le pasaremos model.parameters(). Pero podríamos querer tal vez sólo entrenar las últimas capas, o algunas capas en específico. El paquete PyTorch permite esta flexibilidad y especificación para las necesidades del usuario. A su vez, debemos definir cuál va a ser la tasa de aprendizaje a utilizar en lr.
learning_rate = 2e-3
criterion = nn.HuberLoss()
optimizer = torch.optim.RMSprop(model.parameters(), lr=learning_rate)
Loop de entrenamiento#
Finalmente estamos armados de las herramientas necesarias para entrenar nuestro modelo de aprendizaje automático con PyTorch. En este caso, armé una función que realiza el loop de entrenamiento, ya que más adelante la vamos a utilizar para entrenar el mismo modelo pero con diferentes funciones de costo y distintos algorítmos de optimización. Cuando una tarea hay que hacerla más de una vez, hay que plantearse si no es conveniente escribirla como una función.
Algo interesante en Python es que si uno pasa como argumento una instancia de una clase, entonces la instancia se actualizará en el entorno global si sufre alguna modificación dentro de la función. Esto escapa un poco las reglas de los scopes de las funciones, pero es útil, ya que no debo devolver el modelo como resultado de la función. Con sólo pasar el modelo como argumento, y habiendo sido instanciado afuera de la función, el entrenamiento modificará los valores de los pesos del modelo fuera de la función.
Luego le pasamos el DataLoader de entrenamiento que generamos anteriormente, los datos de validación, la función de costo, el optimizador a utilizar, el número de épocas que se entrenará y una variable con una lista de índices de época en donde se almacenarán las predicciones del modelo en ese momento, como para ver la evolución de la predicción a medida que se va entrenando.
El loop de entrenamiento consiste principalmente en los 5 pasos que están dentro de una época, y luego se repiten estos pasos por len(train_loader)*epochs cantidad de veces. Aquí hay varias sutilezas que habrá que tener en cuenta. Cuando el modelo se entrena, debemos ponerlo en modo entrenamiento con el método .train(). Esto es una de las funcionalidades heredadas de nn.Module. Cuando el modelo se utiliza para evaluación, debe ponerse en modo de evaluación con el método .eval(). La diferencia entre .train() y .eval() radica principalmente en el carácter estocástico que puedan tener algunas capas de la architectura. En el modo train, esta estocasticidad está activada, mientras que en eval esta estocasticidad estará desactivada. Esto es especialmente importante cuando se utiliza dropout, o normalización por batch, pero como no nos meteremos en estos temas, lo dejo mencionado aquí. Si nos será importante cuando veamos redes neuronales bayesianas.
El primer paso del loop de entrenamiento suele ser el de resetear los gradientes acumulados para evitar estimaciones erróneas del gradiente, mediante optimizer.zero_grad(). El segundo paso suele ser el de hacer un paso hacia adelante en el modelo con los datos del batch. Cuando tenemos las predicciones del batch junto a los valores reales, podemos realizar el cálculo de la función de costo, nuestro criterio de optimización especificado anteriormente. Una vez que calculamos el valor de la función de costo para este batch, podemos pasar al siguiente paso que es hacer el paso hacia atrás, para calcular cómo es que se ve afectada la función de costo por los cambios en los parámetros optimizables del modelo. Esto se llama retropropagación y lo veremos la semana que viene en más detalle. El paso es loss.backward(). Mediante este llamado resulta posible entonces estimar el gradiente en el punto actual del espacio de los parámetros y el siguiente paso del loop de entrenamiento es entonces realizar el paso en la dirección opuesta al gradiente (o la definición de paso del método de optimización elegido) con optimizer.step().
Estos son los pasos principales del loop de entrenamiento. Sin embargo, podemos también evaluar cómo está siendo el proceso de entrenamiento y cómo está funcionando el modelo con los datos de evaluación. Esto es lo que se hace en las siguientes líneas del código. Fijarse que, cuando uno hace cálculos en modo evaluación o para entender cómo está funcionando el modelo, no es necesario calcular los gradientes ni alterar los resultados de gradiente almacenados, ya que esto sólo es útil para la optimización de los parámetros. Por ende, se utiliza el modificador de entorno with torch.no_grad(): que cancela el cálculo de gradientes para aquellos tensores que tengan almacenados los gradientes o estén incluídos en el grafo acíclico direccionado.
def entrenar_modelo(modelo, train_loader, val_dataset, criterion, optimizer, epochs=1000, saved_epochs=[200, 500, 1000]):
loss_history = []
val_loss_history = []
saved_predictions = {}
for epoch in range(1, epochs + 1):
modelo.train() # modo entrenamiento
epoch_loss = 0.0
for xb, yb in train_loader:
# ---- paso 1: resetear gradientes acumulados
optimizer.zero_grad()
# ---- paso 2: forward
y_pred = modelo(xb)
# ---- paso 3: calcular pérdida
loss = criterion(y_pred, yb)
# ---- paso 4: backward
loss.backward()
# ---- paso 5: actualizar parámetros
optimizer.step()
epoch_loss += loss.item() * xb.size(0)
epoch_loss /= len(dataset)
loss_history.append(epoch_loss)
modelo.eval() # Pasar a evaluación para fijar capas estocásticas como dropout o batchnorm
val_loss = 0.0
with torch.no_grad():
for xb, yb in val_dataset:
y_pred = modelo(xb)
loss = criterion(y_pred, yb)
val_loss += loss.item() * xb.size(0)
val_loss /= len(val_dataset)
val_loss_history.append(val_loss)
if epoch % 500 == 0:
print(f"Época {epoch:03d} | {criterion.__class__.__name__} entrenamiento: {epoch_loss:.6f} | {criterion.__class__.__name__} Prueba: {val_loss:.6f}")
# Guardamos snapshots del modelo para mostrar cómo mejora el ajuste
if epoch in saved_epochs:
with torch.no_grad():
y_snapshot = model(val_dataset[:][0]).cpu().numpy().squeeze()
saved_predictions[epoch] = y_snapshot.copy()
return loss_history, val_loss_history, saved_predictions
loss_history, val_loss_history, saved_predictions = entrenar_modelo(model, train_loader, val_dataset, criterion, optimizer, epochs=epochs, saved_epochs=saved_epochs)
Época 500 | HuberLoss entrenamiento: 0.391917 | HuberLoss Prueba: 0.578990
Época 1000 | HuberLoss entrenamiento: 0.380854 | HuberLoss Prueba: 0.551933
Época 1500 | HuberLoss entrenamiento: 0.353139 | HuberLoss Prueba: 0.543331
Época 2000 | HuberLoss entrenamiento: 0.294674 | HuberLoss Prueba: 0.466316
Época 2500 | HuberLoss entrenamiento: 0.309852 | HuberLoss Prueba: 0.396323
Época 3000 | HuberLoss entrenamiento: 0.274443 | HuberLoss Prueba: 0.348708
Época 3500 | HuberLoss entrenamiento: 0.262001 | HuberLoss Prueba: 0.705030
Época 4000 | HuberLoss entrenamiento: 0.258914 | HuberLoss Prueba: 0.286248
Graficar resultados#
Una vez finalizado el entrenamiento, y habiendo pensado qué es lo que vamos a querer ver de los resultados, podemos graficar aquellas cantidades a las cuáles le seguimos sus valores a lo largo del loop de entrenamiento. Entre ellas, graficaremos al valor de la función de costo en función de la época y a las predicciones del modelo en función de la cantidad de épocas de entrenamiento.
fig, (ax1, ax2) = plt.subplots(nrows=2, figsize=(12, 8))
plt.tight_layout()
# Datos reales
ax1.plot(xdata, ydata, color="black", label="Datos de prueba")
# Colores para snapshots
colors = [plt.cm.jet((i + 1) / float(len(saved_epochs) + 1)) for i in range(len(saved_epochs))]
# Curvas predichas en distintos momentos del entrenamiento
for i, epoch in enumerate(saved_epochs):
ax1.plot(val_dataset[:][0], saved_predictions[epoch], 'o', color=colors[i], label=f"Epoch {epoch}", ms=3, alpha=0.7)
ax2.plot(epoch, loss_history[epoch - 1], color=colors[i], marker="o")
ax1.set_title(f"{nb_layers} capas ocultas, {nb_nodes} nodos por capa, ReLU")
ax1.set_xlabel("x")
ax1.set_ylabel("funcion_compleja(x)")
ax1.set_xlim(-10, 13)
ax1.grid(True)
ax1.legend(loc="upper right", title="Snapshots")
# Historia de la loss
ax2.plot(loss_history, color="black")
ax2.set_xlabel("Epoch")
ax2.set_ylabel("Loss (MSE)")
ax2.set_yscale("log")
ax2.grid(True)
plt.show()
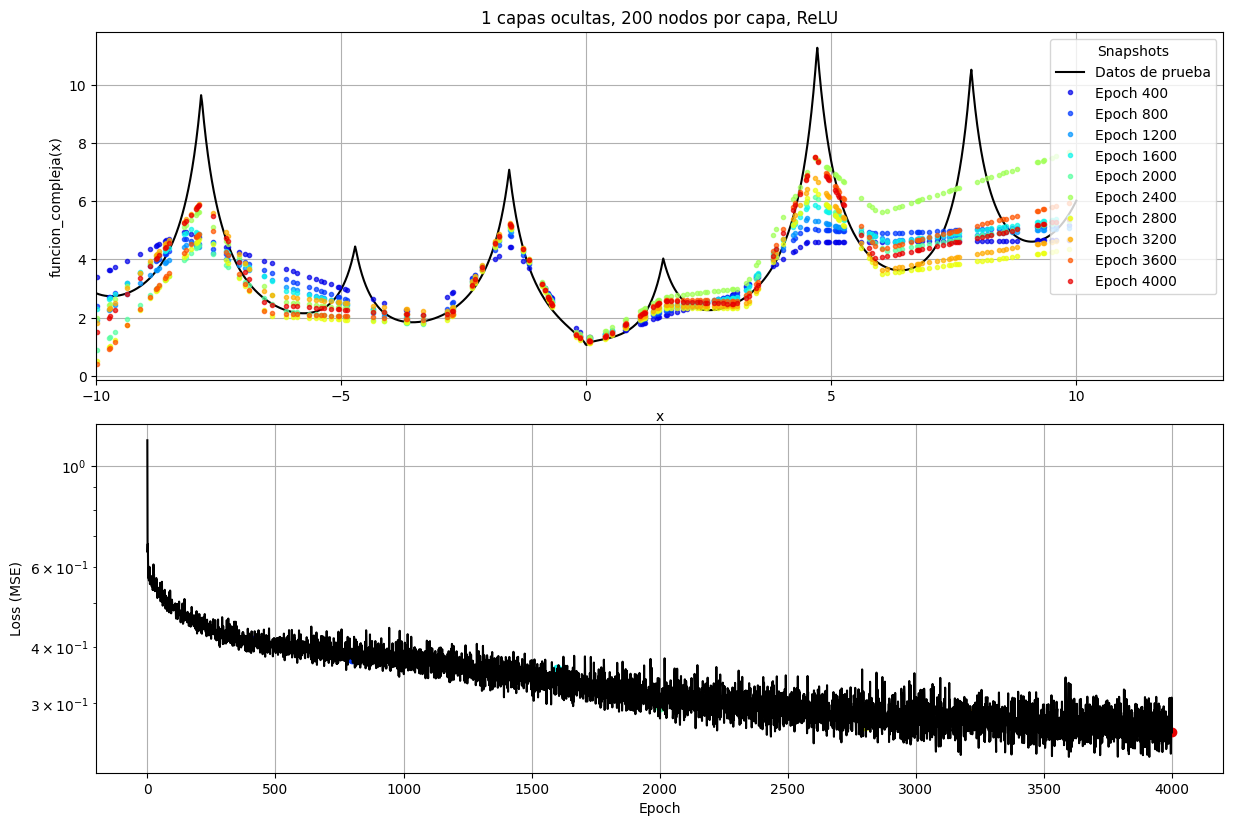
Podemos ver que el modelo aprende de los datos con este loop de entrenamiento ya que la función de costo es minimizada en el proceso. Además vemos gráficamente que los valores predichos se van acercando a los datos reales a medida que pasan las épocas. Sin embargo, vemos que el modelo carece de la capacidad de representar con exactitud los datos observados. Esto se debe principalmente a la arquitectura planteada. El teorema de aproximación universal no nos dice que este modelo sea correcto, sino que existe uno (y al parecer no es este). Podríamos seguir aumentando la cantidad de neuronas dentro de la capa para aumentar la expresividad del modelo y así llegar a una predicción más razonable para los datos provistos.
Sin emabrgo, una manera más sencilla de agregar complejidad a un modelo y por ende expresividad en su resultado, es al aumentar la cantidad de capas, ya que involucra mayor cantidad de funciones de activación no lineales. A continuación, exploramos un modelo en donde se interponen 3 capas ocultas con 30 nodos, en vez de una sola de 100.
Además, como no sabemos bien qué algoritmo de optimización utilizar ni qué criterio nos conviene, utilizaremos un conjunto de criterios y optimizadores, y entrenaremos el nuevo modelo utilizando las combinaciones posibles. Esto sirve para ver la utilidad y el potencial que tiene el paquete de PyTorch para implementar entrenamientos complejos con una interfaz sencilla.
Nota: En el caso de los optimizadores, utilicé lo que se llama en python funciones lambda. lambda es una palabra reservada de python que permite definir una función inline, es decir en una sola línea. la variable que le sigue a lambda es la variable de la función, y lo que sigue después del \(:\) es lo que debe realizar la función sobre la variable definida. Como estos optimizadores precisan de los parámetros del modelo para saber qué optimizar, y en cada loop vamos a estar instanciando un nuevo modelo, entonces debo dejar el grado de libertad de pasar los parámetros durante la iteración de criterios y optimizadores. Esto es lo que sucede en la línea optimizer = optimizer_fn(models[label].parameters()). Luego utilizamos la función para entrenar modelo que ya creamos anteriormente para entrenarlo, y almacenamos los resultados en diccionarios. Con esto, podemos graficar los resultados de las curvas de entrenamiento para las distintas combinaciones de funciones de costo y algoritmos de optimización.
lr = 1e-3
nb_layers = 3
nb_nodes = 30
seed = 30
epochs = 2_000
criterions = [nn.MSELoss, nn.HuberLoss, nn.L1Loss]
optimizers = [lambda params: torch.optim.Adam(params, lr),
lambda params: torch.optim.SGD(params, lr),
lambda params: torch.optim.RMSprop(params, lr)]
torch.manual_seed(seed)
models, histories, test_histories, all_saved_predictions = {}, {}, {}, {}
plt.figure(figsize=(14, 6))
for criterion in criterions:
criterion = criterion()
for optimizer_fn in optimizers:
label =f"{criterion.__class__.__name__}_{optimizer.__class__.__name__}"
models[label] = MLP1D(input_dim=X.shape[1], nb_layers=nb_layers, nb_nodes=nb_nodes)
optimizer = optimizer_fn(models[label].parameters())
print(f"Entrenando con {criterion.__class__.__name__} y {optimizer.__class__.__name__}")
histories[label], test_histories[label], all_saved_predictions[label] = entrenar_modelo(models[label], train_loader, val_dataset, criterion, optimizer, epochs=epochs)
plt.plot(histories[label], label=label, alpha=0.8)
plt.yscale("log")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Comparación de funciones de pérdida y optimizadores")
plt.grid(True)
plt.legend()
plt.show()
Entrenando con MSELoss y Adam
Época 500 | MSELoss entrenamiento: 0.507572 | MSELoss Prueba: 0.532652
Época 1000 | MSELoss entrenamiento: 0.203670 | MSELoss Prueba: 0.218853
Época 1500 | MSELoss entrenamiento: 0.091979 | MSELoss Prueba: 0.125494
Época 2000 | MSELoss entrenamiento: 0.098490 | MSELoss Prueba: 0.076684
Entrenando con MSELoss y SGD
Época 500 | MSELoss entrenamiento: 1.741924 | MSELoss Prueba: 2.604781
Época 1000 | MSELoss entrenamiento: 1.443576 | MSELoss Prueba: 2.118594
Época 1500 | MSELoss entrenamiento: 1.310641 | MSELoss Prueba: 1.826148
Época 2000 | MSELoss entrenamiento: 1.097743 | MSELoss Prueba: 1.552078
Entrenando con MSELoss y RMSprop
Época 500 | MSELoss entrenamiento: 0.548189 | MSELoss Prueba: 0.360436
Época 1000 | MSELoss entrenamiento: 0.210837 | MSELoss Prueba: 0.126508
Época 1500 | MSELoss entrenamiento: 0.111425 | MSELoss Prueba: 0.075845
Época 2000 | MSELoss entrenamiento: 0.107163 | MSELoss Prueba: 0.043024
Entrenando con HuberLoss y Adam
Época 500 | HuberLoss entrenamiento: 0.185935 | HuberLoss Prueba: 0.227927
Época 1000 | HuberLoss entrenamiento: 0.048141 | HuberLoss Prueba: 0.065709
Época 1500 | HuberLoss entrenamiento: 0.025445 | HuberLoss Prueba: 0.030722
Época 2000 | HuberLoss entrenamiento: 0.012509 | HuberLoss Prueba: 0.021050
Entrenando con HuberLoss y SGD
Época 500 | HuberLoss entrenamiento: 0.539435 | HuberLoss Prueba: 0.802734
Época 1000 | HuberLoss entrenamiento: 0.519103 | HuberLoss Prueba: 0.784341
Época 1500 | HuberLoss entrenamiento: 0.498194 | HuberLoss Prueba: 0.760124
Época 2000 | HuberLoss entrenamiento: 0.473401 | HuberLoss Prueba: 0.733879
Entrenando con HuberLoss y RMSprop
Época 500 | HuberLoss entrenamiento: 0.223237 | HuberLoss Prueba: 0.295823
Época 1000 | HuberLoss entrenamiento: 0.107559 | HuberLoss Prueba: 0.064399
Época 1500 | HuberLoss entrenamiento: 0.045521 | HuberLoss Prueba: 0.163246
Época 2000 | HuberLoss entrenamiento: 0.031106 | HuberLoss Prueba: 0.017730
Entrenando con L1Loss y Adam
Época 500 | L1Loss entrenamiento: 0.445026 | L1Loss Prueba: 0.588049
Época 1000 | L1Loss entrenamiento: 0.331607 | L1Loss Prueba: 0.391775
Época 1500 | L1Loss entrenamiento: 0.246960 | L1Loss Prueba: 0.312347
Época 2000 | L1Loss entrenamiento: 0.213248 | L1Loss Prueba: 0.232820
Entrenando con L1Loss y SGD
Época 500 | L1Loss entrenamiento: 0.829389 | L1Loss Prueba: 1.198932
Época 1000 | L1Loss entrenamiento: 0.813931 | L1Loss Prueba: 1.185567
Época 1500 | L1Loss entrenamiento: 0.780831 | L1Loss Prueba: 1.140801
Época 2000 | L1Loss entrenamiento: 0.729293 | L1Loss Prueba: 1.087875
Entrenando con L1Loss y RMSprop
Época 500 | L1Loss entrenamiento: 0.331064 | L1Loss Prueba: 0.415468
Época 1000 | L1Loss entrenamiento: 0.236276 | L1Loss Prueba: 0.275803
Época 1500 | L1Loss entrenamiento: 0.163540 | L1Loss Prueba: 0.180031
Época 2000 | L1Loss entrenamiento: 0.125988 | L1Loss Prueba: 0.248645
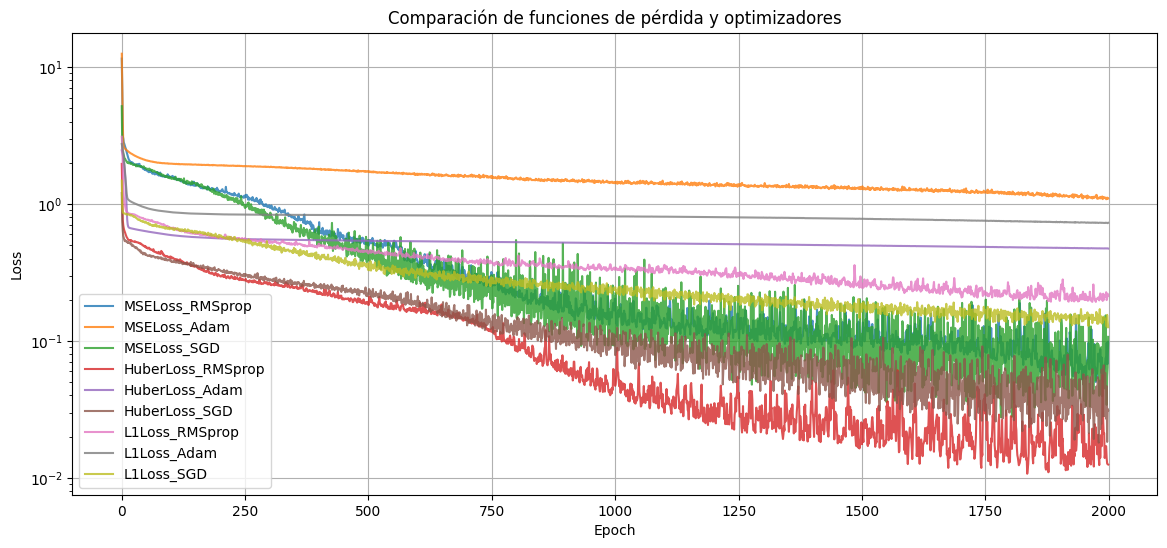
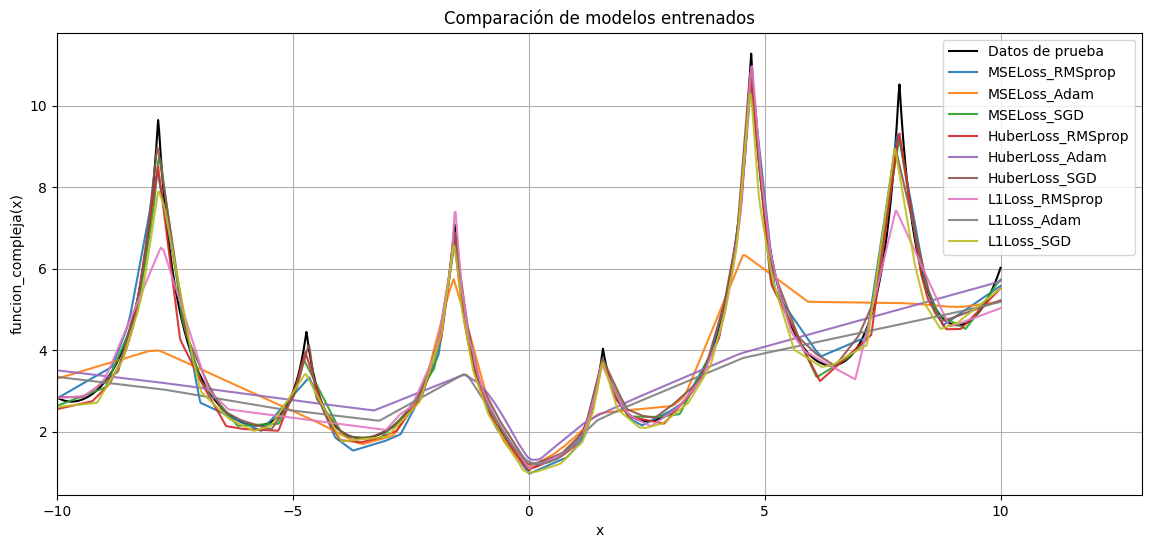
De este resultado, vemos que para este problema en particular y estos datos, el algoritmo RMSprop es el que mejor funciona (mejor mínimo encuentra) combinado junto con la pérdida de Huber. Podemos imprimir el promedio de los 10 últimos valores alcanzados por los algoritmos de optimización para las distintas funciones de costo:
for label, test_history in test_histories.items():
print(f"{label}: {np.array(test_history[-10:]).mean():.6f}")
MSELoss_RMSprop: 0.114410
MSELoss_Adam: 1.543311
MSELoss_SGD: 0.065113
HuberLoss_RMSprop: 0.023325
HuberLoss_Adam: 0.733618
HuberLoss_SGD: 0.064258
L1Loss_RMSprop: 0.259338
L1Loss_Adam: 1.089806
L1Loss_SGD: 0.222051
También podemos aprovechar y graficar las predicciones de los distintos modelos, como para corroborar que efectivamente esta combinación es la que mejor anduvo:
plt.figure(figsize=(14, 6))
plt.plot(xdata, ydata, color="black", label="Datos de prueba")
for label, model in models.items():
with torch.no_grad():
y_pred = model(torch.tensor(xdata).float()).cpu().numpy().squeeze()
plt.plot(xdata, y_pred, label=label, alpha=0.9)
plt.xlabel("x")
plt.ylabel("funcion_compleja(x)")
plt.title("Comparación de modelos entrenados")
plt.xlim(-10, 13)
plt.grid(True)
plt.legend()
plt.show()
Selección de modelo, optimización y función de costo final#
Como pueden ver, utilizamos los datos de evaluación para determinar mucho más que los parámetros del modelo y su arquitectura. Podríamos inclusive haber probado distintas arquitecturas en la optimización, distintas tasas de aprendizaje, tamaño de batch, etc. Para aquellos intereasdos, existen librerías en python, como Optuna que ayudan a la automatización de este tipo de optimización de hiper-parámetros en PyTorch y otras librerías.
Una vez seleccionada la mejor combinación, entonces podemos hacer un último entrenamiento:
epochs = 6_000
modelo_final = MLP1D(input_dim=X.shape[1], nb_layers=nb_layers, nb_nodes=nb_nodes)
criterion = nn.HuberLoss()
optimizer = torch.optim.RMSprop(modelo_final.parameters(), lr=0.001)
history, test_history, saved_predictions = entrenar_modelo(modelo_final, train_loader, val_dataset, criterion, optimizer, epochs=epochs)
Época 500 | HuberLoss entrenamiento: 0.198416 | HuberLoss Prueba: 0.220682
Época 1000 | HuberLoss entrenamiento: 0.089835 | HuberLoss Prueba: 0.091314
Época 1500 | HuberLoss entrenamiento: 0.040773 | HuberLoss Prueba: 0.062721
Época 2000 | HuberLoss entrenamiento: 0.026785 | HuberLoss Prueba: 0.071070
Época 2500 | HuberLoss entrenamiento: 0.025507 | HuberLoss Prueba: 0.011510
Época 3000 | HuberLoss entrenamiento: 0.032008 | HuberLoss Prueba: 0.023559
Época 3500 | HuberLoss entrenamiento: 0.011666 | HuberLoss Prueba: 0.108147
Época 4000 | HuberLoss entrenamiento: 0.016679 | HuberLoss Prueba: 0.029226
Época 4500 | HuberLoss entrenamiento: 0.007113 | HuberLoss Prueba: 0.016489
Época 5000 | HuberLoss entrenamiento: 0.018181 | HuberLoss Prueba: 0.010823
Época 5500 | HuberLoss entrenamiento: 0.012233 | HuberLoss Prueba: 0.021385
Época 6000 | HuberLoss entrenamiento: 0.003059 | HuberLoss Prueba: 0.023478
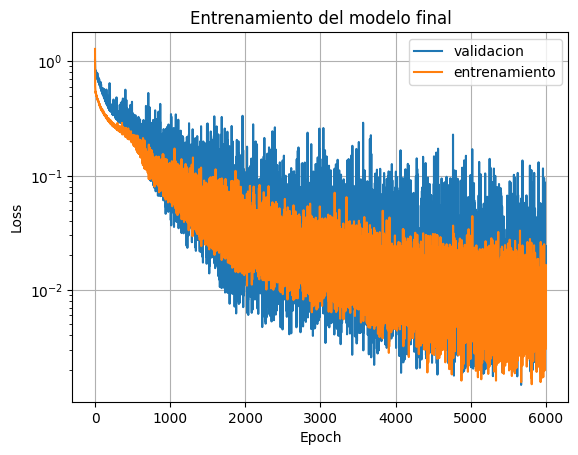
Analizando las curvas de aprendizaje, vemos que la función de costo es minimizada tanto para el conjunto de entrenamiento como el de validación.
plt.plot(test_history, label="validacion")
plt.plot(history, label="entrenamiento")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Entrenamiento del modelo final")
plt.grid(True)
plt.legend()
plt.yscale('log')
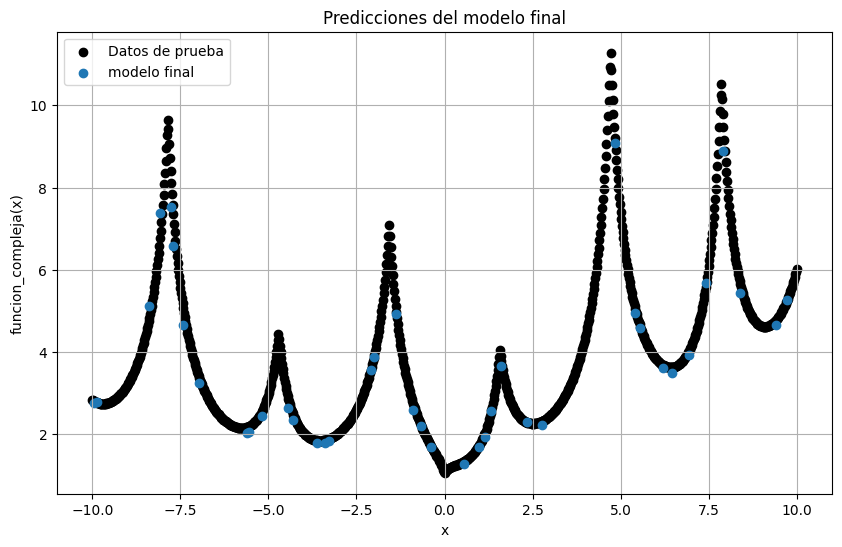
Finalmente, podemos utilizar los datos de prueba para verificar que el modelo funcionó como esperado
with torch.no_grad():
modelo_final.eval()
y_pred = modelo_final(test_dataset[:][0]).cpu().numpy().squeeze()
plt.figure(figsize=(10, 6))
plt.scatter(xdata, ydata, color="black", label="Datos de prueba")
plt.scatter(test_dataset[:][0], y_pred, label = "modelo final")
plt.xlabel("x")
plt.ylabel("funcion_compleja(x)")
plt.title("Predicciones del modelo final")
plt.grid()
plt.legend()
plt.show()
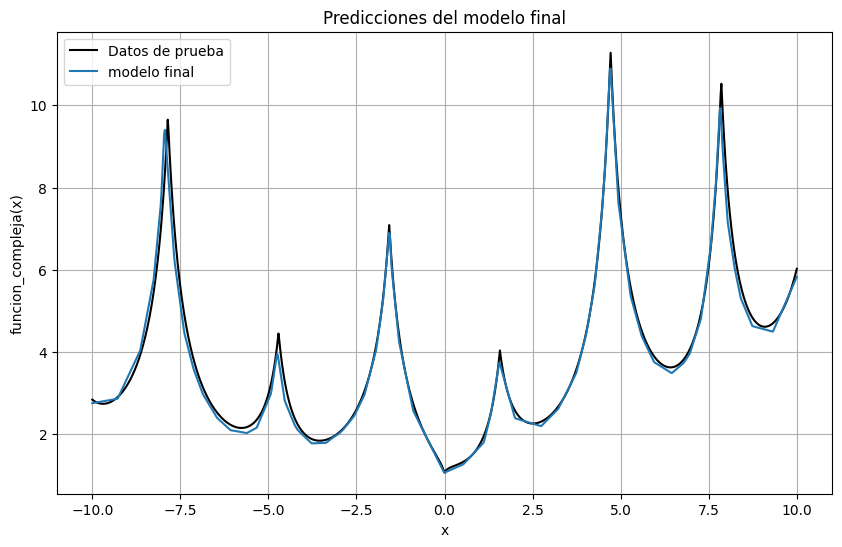
En este caso, como es una función simple de una variable, podemos también predecir los valores para todo el rango de datos de entrada y comparar con el resultado real
plt.figure(figsize=(10, 6))
plt.plot(xdata, ydata, color="black", label="Datos de prueba")
with torch.no_grad():
modelo_final.eval()
y_pred = modelo_final(torch.tensor(xdata).float()).cpu().numpy().squeeze()
plt.plot(xdata, y_pred, label = "modelo final")
plt.grid()
plt.xlabel("x")
plt.ylabel("funcion_compleja(x)")
plt.title("Predicciones del modelo final")
plt.legend()
plt.show()
<matplotlib.legend.Legend at 0x36d6a2d20>
Guardar el modelo#
Finalmente, resulta conveniente saber cómo guardar un modelo en PyTorch, y también como cargarlo nuevamente para continuar entrenamiento o bien para utilizarlo en modo inferencia.
# Guardar parametros del modelo (sin arquitectura)
torch.save(modelo_final.state_dict(), "modelo_final.pth")
# opcion guardar todo el modelo con arquitectura
torch.save(modelo_final, "modelo_completo.pth")
# Cargar modelo a partir de los parámetros guardados (necesita definir la arquitectura)
nuevo_modelo = MLP1D(input_dim=X.shape[1], nb_layers=nb_layers, nb_nodes=nb_nodes)
nuevo_modelo.load_state_dict(torch.load("modelo_final.pth", weights_only=True))
nuevo_modelo.eval()
# Cargar modelo completo (incluye arquitectura)
nuevo_modelo_completo = torch.load("modelo_completo.pth", weights_only=False)
nuevo_modelo_completo.eval()
MLP1D(
(net): Sequential(
(0): Linear(in_features=1, out_features=30, bias=True)
(1): ReLU()
(2): Linear(in_features=30, out_features=30, bias=True)
(3): ReLU()
(4): Linear(in_features=30, out_features=30, bias=True)
(5): ReLU()
(6): Linear(in_features=30, out_features=1, bias=True)
)
)
plt.figure(figsize=(10, 6))
plt.plot(xdata, ydata, color="black", label="Datos de prueba")
with torch.no_grad():
nuevo_modelo.eval()
y_pred = nuevo_modelo(torch.tensor(xdata).float()).cpu().numpy().squeeze()
plt.plot(xdata, y_pred, label = "modelo final")
plt.grid()
plt.xlabel("x")
plt.ylabel("funcion_compleja(x)")
plt.title("Predicciones del modelo final")
plt.legend()
plt.show()