4. Modelos probabilísticos#
Diapositivas teórico:
Notebooks teórico-práctico:
Guía de trabajo práctico:
4.1. Aprender distribuciones#
En muchas áreas de la física, el objetivo central no es únicamente predecir un valor específico, sino comprender y modelar la incertidumbre inherente a los sistemas naturales. Los fenómenos físicos suelen estar influenciados por múltiples fuentes de variabilidad: ruido experimental, condiciones iniciales desconocidas, interacciones microscópicas no observables o incluso naturaleza intrínsecamente estocástica del sistema.
Un modelo probabilístico permite representar el estado de un sistema físico mediante una distribución de probabilidad en lugar de un único valor determinista. Esto resulta especialmente natural en física estadística, mecánica cuántica y termodinámica, donde las magnitudes de interés se describen en términos de distribuciones y promedios. Por ejemplo, en lugar de predecir exactamente la posición de una partícula, se modela la probabilidad de encontrarla en una determinada región del espacio.
La motivación principal de los modelos probabilísticos radica en su capacidad para incorporar conocimiento previo del sistema, formular hipótesis físicas y actualizar dichas creencias a partir de datos experimentales. A partir de observaciones, el aprendizaje de una distribución de probabilidad permite capturar patrones, correlaciones y estructuras subyacentes que no son evidentes a nivel determinista. De esta manera, los modelos probabilísticos proporcionan un marco unificado para inferencia, predicción y toma de decisiones, manteniendo una estrecha conexión con los principios fundamentales de la física.
La motivación para utilizar modelos probabilísticos va más allá de la física. En disciplinas como la biología, la economía, la robótica o el aprendizaje automático, los datos suelen ser incompletos, ruidosos y de alta dimensionalidad. En estos escenarios, los enfoques deterministas resultan insuficientes para capturar la complejidad de los procesos subyacentes. Los modelos probabilísticos ofrecen un marco flexible para representar múltiples posibles resultados, cuantificar la incertidumbre de las predicciones y generar muestras coherentes con los datos observados.
Desde una perspectiva moderna, muchos de estos modelos se implementan mediante redes neuronales profundas, lo que permite escalar el aprendizaje de distribuciones de probabilidad a espacios de alta dimensión. A continuación, se presentan distintas familias de modelos probabilísticos ampliamente utilizados en aprendizaje automático generativo, cada una con principios y compromisos diferentes entre expresividad, eficiencia computacional e interpretabilidad.
4.2. Diseñar una función de costo adecuada#
El límite inferior de la evidencia (ELBO, del inglés evidence lower bound) es una cantidad importante que permite el entrenamiento de modelos probabilísticos y que veremos en detalle a continuación.
En un modelo de variable latente, suponemos que nuestros dato observado \(x\) es una realización de una variable aleatoria \(X\). Más aún, pensamos que existe otra variable aleatoria \(Z\) cuya probabilidad de distribución conjunta está determinada por \(p_\theta(X,Z)\), en donde \(\theta\) son los parámetros que parametrizan la distribución. Desafortunadamente, nuestros datos medidos u observados son sólo una realización de \(X\) y no de \(Z\), por lo que \(Z\) permanece no observada o latente.
Supongamos que queremos calcular la distribución de probabilidad posterior \(p_\theta(z|x)\) dado algún valor fijo de \(\theta\). Es decir, cuál es la probabilidad de observar \(Z=z\) dado que se observó \(X=x\) para todo valor de \(z\) y \(x\). Este problema se puede plantear utilizando lo que se conoce como inferencia variacional y que describiremos en breves.
Ahora supongamos que no conocemos \(\theta\), pero queremos encontrar el estimador de máxima verosimilitud de \(\theta\), i.e. \(\text{argmax}_{\theta} l(\theta)\), en donde \(l(\theta)\) es la función de log-verosimilitud, definida como
Este problema se puede plantear utilizando la maximicación del valor esperado o esperanza.
Tanto la inferencia variacional como la maximización del valor esperado se basan en el límite inferior de la evidencia ELBO.
Para entender ELBO hay que primero definir qué es la evidencia. La evidencia es el nombre que se le da a la función de verosimilitud evaluada en un vector de parámetros \(\theta\) fijo. Esto se denota poniendo a \(\theta\) del lado derecho del símbolo \(;\) en la expresión
Intuitivamente, si elegimos el modelo correcto para \(p\) y \(\theta\), esperaríamos que la probabilidad marginal de observar los datos \(x\) que observamos sea muy alta. Por lo tanto, un valor alto para \(\log p_\theta(x)\) indica de cierta manera que estamos en la dirección correcta al haber seleccionado el modelo \(p\) y los parámetros \(\theta\) para estos datos. Es decir, que esta cantidad es una “evidencia” que hemos elegido el modelo correcto para los datos.
Ahora supongamos que \(Z\) sigue una distribución condicionada a los datos observados denotada por \(q_\phi(z|x)\), parametrizada por \(\phi\). Utilizamos un truco matemático para introducir esta cantidad en la forma integral de la marginalización de \(\log p_\theta(x)\). Como \(\frac{q_\phi(z|x)}{q_\phi(z|x)}=1\), podemos escribir:
en donde para pasar a la desigualdad hemos utilizado la desigualdad de Jensen [1]. Definimos entonces la cota inferior para la evidencia (Evidence Lower Bound) a
ya que acabamos de probar que es una cota inferior a la evidencia. Resulta que la diferencia entre la evidencia y el ELBO es exactamente la divergencia de Kullback-Leibler (KL) entre \(p_\theta(z|x)\) y \(q_\phi(z|x)\)! Esto se puede probar partiendo desde la definición de la divergencia de Kullback-Leibler de estas distribuciones:
Esta resulta una identidad clave, ya que ahora podemos decir con exactitud que la evidencia es la suma del ELBO + la divergencia de KL. Cuando el objetivo es maximizar la evidencia, resulta factible entonces maximizar el ELBO y de esta manera la divergencia de KL va a medir cuán lejos está la aproximación \(q(z)\) de la verdadera probabilidad posterior. Además vemos que Maximizar el ELBO equivale a minimizar la divergencia de KL.
4.2.1. Inferencia Variacional#
La inferencia variacional sirve para estimar una distribución posterior cuando calcularla explícitamente resulta inviable. Como habíamos mencionado, queremos calcular \(P(Z|X)\), para \(Z\) variable latente y \(X\) variable observada. Idealmente, si conociesemos todos los términos, debido al Teorema de Bayes,
pero el problema usual es que el denominador \(p(x)\) no tiene una forma cerrada. La inferencia variacional intenta encontrar otra distribución \(q(z|x)\) que se asemeja “lo más posible” a \(p(z|x)\). Para esto, utiliza a la divergencia de Kullback-Leibler como una medida de “cercanía” entre dos distribuciones. Por lo tanto en la inferencia variacional se intenta encontrar
y luego devuelve \(\hat q (z|x)\) como la aproximación a la distribución posterior \(p(z|x)\). Por ende, en la inferencia variacional se minimiza la divergencia de KL, lo que acabamos de ver que es equivalente a maximizar el ELBO.
Conceptualmente, la inferencia variacional nos permite formular el problema de inferencia Bayesiana aproximada como un problema de optimización, y para esto, sabemos muy bien como utilizar PyTorch!
4.3. Autoencoder Variacional (VAE)#
Los autoencoders variacionales fueron introducidos en 2013 por Kingma et al. en su artículo “Auto-Encoding Variational Bayes” [2]. En su forma más simple un Autoencoder Variacional (VAE, del inglés Variational Autoencoder) es un modelo probabilístico que encuentra una representación latente de baja dimensionalidad de los datos [3]. Son utilizados para reducción de dimensionalidad como así también como modelos generativos. Un VAE es un tipo de Autoencoder, es decir un modelo que toma un vector de entrada \(\vec{x}\), lo comprime a un espacio de menor dimensionalidad \(\vec{z}\) y luego lo descomprime de nuevo en el intento de devolver nuevamente el vector \(\vec{x}\). La figura a continuación muestra la arquitectura típica de un autoencoder:
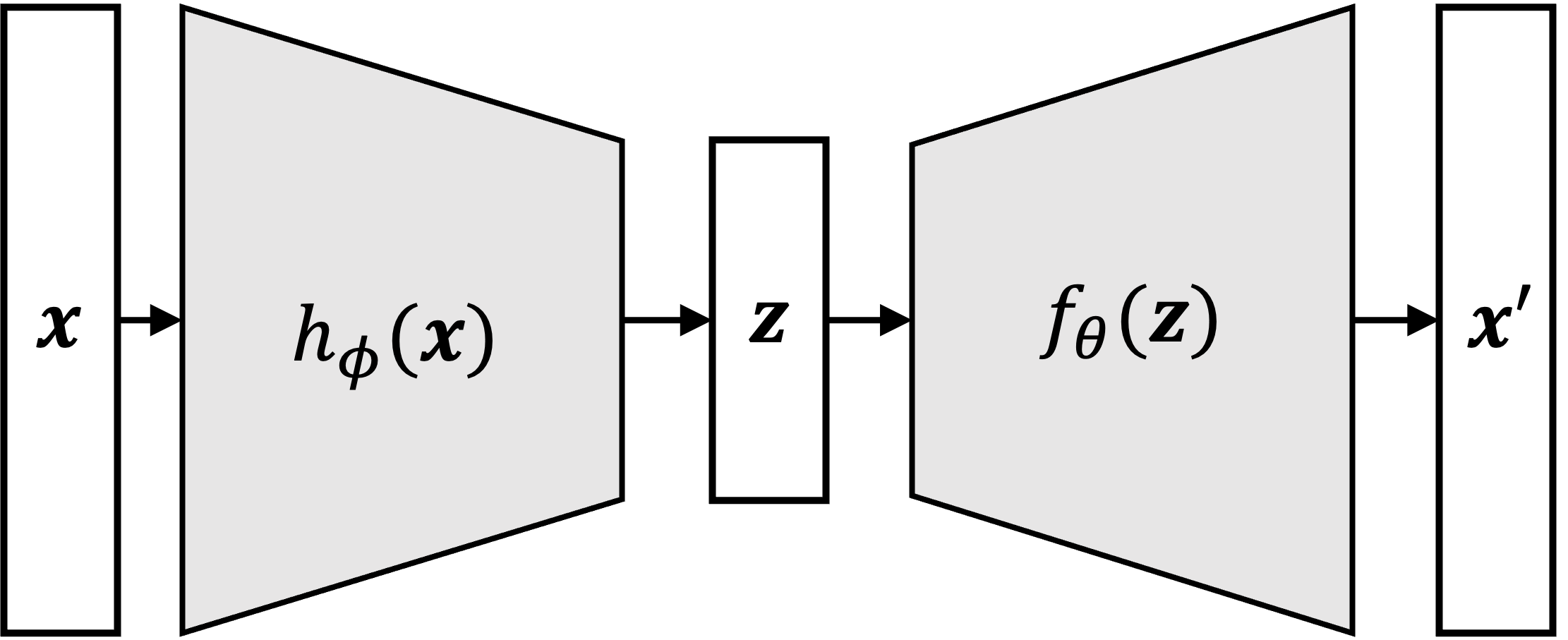
En este esquema se muestrá al vector de entrada \(\vec{x}\) que se alimenta a una función, usualmente una red neuronal, \(h_{\phi}(\vec{x})\) para generar un vector de salida de menor dimensionalidad \(\vec z\) y luego otra función, también red neuronal, \(f_\theta\) que toma al vector \(\vec{z}\) y lo descomprime hacia una aproximación \(\vec{x'}\) de \(\vec{x}\). Las variables \(\phi\) y \(\theta\) denotan los parámetros de las redes neuronales. A la red neuronal \(h_{\phi}(\vec{x})\) se le suele llamar encoder (de ahí el nombre del modelo) ya que codifica la información inicial en un espacio de menor dimensionalidad, y a la red \(f_\theta(\vec{z})\) reconstructora de la información se la suele llamar decoder ya que decodifica la información del espacio comprimido al espacio original, en un intento de recuperar la información inicial.
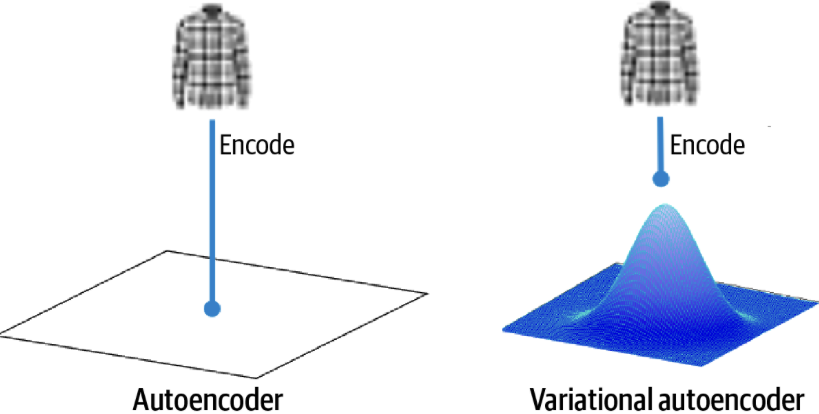
Los VAE extienten la idea del autoencoder para transformarlo en un modelo probabilístico en donde se aprenden distribuciones. Describen la probabilidad conjunta \(p(\vec{x},\vec{z})\) para las muestras \(\vec{x}\) y sus variables latentes asociadas \(\vec{z}\). Es decir, en un VAE no se produce un punto fijo en el espacio latente sino una distribución de probabilidad, como se representa en la siguiente figura.
¿Cómo se logra esto? Bueno, definiendo una función de costo adecuarda para aprender distribuciones de probabilidad: mediante el uso de la divergencia de Kullback-Leibler que hemos visto anteriormente. En los VAE se utilizan dos funciones de costo principales (luego hay mil variaciones y se pueden agregar términos, pero veremos el VAE clásico o vanilla). La primera es un término de pérdida por reconstrucción, como MSE, entre la entrada \(\vec{x}\) y la salida \(\vec{x'}\). Esta la podríamos escribir como
Esto es exactamente lo que hace un autoencoder clásico.
La diferencia está en la inclusión de un segundo término que es la divergencia de KL entre la distribución generada por el encoder y una distribución de referencia que usualmente se utiliza la Normal estándar. Pero como hemos visto, en la inferencia variacional minimizar la divergencia de KL es equivalente a maximizar el ELBO.
Como mencionado, típicamente \(\vec{z}\) se toma como un vector de variable aleatorias \(\vec{z}\in \mathbb R^M\) y se utilizan distribuciones gaussianas tanto para la distribución posterior variacional \(q_\phi(\vec{z}|\vec{x})=\mathcal N (\mu_{\phi}(\vec{x}), \text{diag}\left[\sigma_\phi ^2(\vec{x})\right])\) y la distribución apriori para \(\vec z\), \(p(\vec{z})=\mathcal N (0, \mathbf I)\). Tanto \(\mu_{\phi}(\vec{x})\) como \(\sigma_\phi ^2(\vec{x})\) se obtienen de la salida de \(h_\phi(\vec{x})\), es decir se diseña la arquitectura para que \(h_\phi(\vec{x})\) produzca \(2M\) salidas que generan ambos vectores que definen la distribución condicional para \(\vec z\) dado \(\vec x\). Que un VAE funcione para aprender distribuciones tiene que ver con la inferencia variacional, y vimos que ésta depende de maximizar el ELBO. Veremos más adelante que resulta más fácil plantear la minimización de la divergencia de KL, pero que de fondo lo que estamos haciendo es inferencia variacional basada en la maximización del ELBO.
Para el caso de la distribución del decoder, \(p_\theta(\vec{x}|\vec z)\) tenemos que tener un leve cuidado ya que dependerá de la naturaleza de nuestros datos \(\vec{x}\). Si \(\vec{x}\) son imágenes, entonces tenemos pixeles y \(\vec x \in \{0,1,\dots,255\}^D\). Por ende, no podemos utilizar una distribución normal para la aproximación \(\vec{x'}\). Una distribución posible en este caso sería
donde las probabilidades están dadas por la red neuronal del decoder, i.e. \(\theta(\vec{z})=\text{Softmax}(f_\theta(\vec{z}))\).
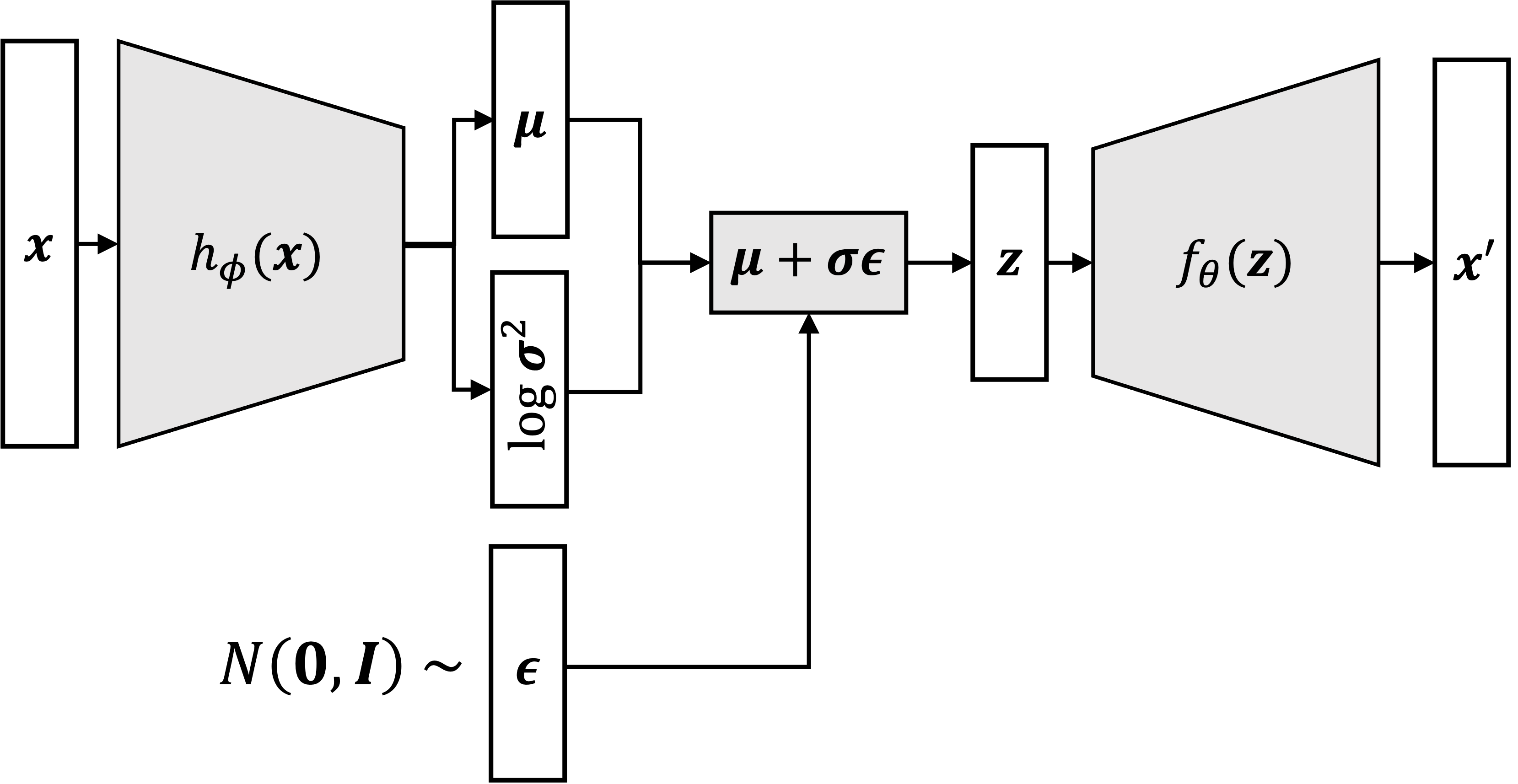
Ya con estas consideraciones, tendríamos todas las expresiones y podríamos calcular el ELBO si pudiesemos calcular los valores esperados de estas cantidades. Pero el problema que tenemos es que este cálculo involucra integrales que no podemos calcular. Acá, vamos a utilizar un truco llamado la reparametrización de una distribución. La idea se basa en escribir a \(\vec{z}\) como
con \(\epsilon \sim \mathcal N(0,I)\). Si muestreamos \(\epsilon\), entonces \(\vec{z} \sim \mathcal N (\mu, \sigma^2)\). Entonces ahora podríamos utilizar una aproximación Monte Carlo a esta integral muestreando de \(p(\epsilon)\) que es bien sencilla. Esto nos permite entonces calcular el gradiente con respecto a nuestra red neuronal, ya que la red encoder produce \(\mu\) y \(\sigma\), todo diferenciable, y luego la red del decoder toma un valor discreto \(\vec{z}\) obtenido por la reparametrización y produce una salida \(\vec{x'}\) (todo diferenciable). Más aún, como aprendemos mediante descenso por gradiente estocástico, es suficiente con que la aproximación de Monte Carlo sea con N=1, es decir que se samplee una vez por batch! La idea al finl se resume un poco en esta imágen (la notación es levemente diferente, pero se entiende). El encoder produce valores para la media y el desvío que produce la distribución latente Gaussiana. Luego se muestrea esta distribución mediante el truco de la reparametrización, agregando un nodo estocástico que produce \(\epsilon\) y luego el decoder produce una imágen correspondiente al vector latente muestreado. Repito, tanto el encoder como el decoder son redes neuronales comúnes, podrían ser MLPs, CNNs, etc.
Bueno, finalmente vamos a derivar la expresión que nos queda para término de pérdida por divergencia de KL que utilizaremos a fines prácticos. Toda esta explicación ha sido como para entender un poco más por qué los VAE funcionan como modelos generativos. A fines prácticos, vamos a ver que
en donde \(\mu_{\phi}(\vec x)_m\) \(\log \sigma_{\phi}(\vec{x})_m^2\) son los elementos de la salida del encoder \(h_{\phi}(\vec x)\) con \(2M\) salidas (ver figura anterior para clarificar).
Demostración (no necesaria, sólo informativa):
Podemos escribir la divergencia KL en dos términos:
Trabajemos el primer término
Para el segundo término, tenemos
Al combinar los dos términos, llegamos a
que al pensar en \(\mu_m\) y \(\sigma_m\) como elementos de la última capa de una red neuronal se transforman en la ecuación de interés.
Finalmente,
4.4. Ejemplo: VAE para generar nuevos números del conjunto MNIST#
MNIST es un conjunto de datos que consiste en imágenes de números escritos a mano. Las imágenes constan de \(28\times28\) pixeles. Vamos a plantear una espacio latente de \(M=50\) (\(\vec{z}\in \mathbb R^{50}\)) y vamos a utilizar una arquitectura de encoder decoder basada en MLP, pero tranquilamente se podría utilizar una basada en CNN ya que contamos con imágenes. Como vamos a usar un MLP, debemos transformar las imágenes (además de normalizarlas) para que sean un vector. A este procedimiento se le suele llamar flatten, resultando en vectores de dimensión \(28\times 28=784\).
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
transforms.Lambda(lambda x: x.view(-1)) # Flatten the image to [784]
])
# 2. Load the training dataset
trainset = torchvision.datasets.MNIST(
root='../data', # A donde se guardan los datos
train=True, # Si queremos la partición de entrenamiento o evaluación
download=True, # descarga de datos si no ya presente
transform=transform # transformaciones a los datos
)
testset = torchvision.datasets.MNIST(
root='../data',
train=False,
download=True,
transform=transform
)
batch_size=128
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)
testloader = DataLoader(testset, batch_size=batch_size, shuffle=False)
# Veeamos 25 casos dle conjunto de entrenamiento
dataiter = iter(trainloader)
image = next(dataiter)
num_samples = 25
sample_images = image[0][:num_samples] # Obtiene las primeras 25 imágenes aplanadas [num_samples, 784]
fig, axes = plt.subplots(5, 5, figsize=(8, 8))
for ax, im in zip(axes.flat, sample_images):
ax.imshow(im.reshape(28, 28), cmap='gray')
ax.axis('off')
plt.tight_layout()
plt.show()
Ahora definimos la arquitectura del VAE como también la función de costo
import torch.nn as nn
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(
self,
x_dim,
hidden_dim,
z_dim=10
):
super(VAE, self).__init__()
# Define capas de encoder
self.enc_layer1 = nn.Linear(x_dim, hidden_dim)
self.enc_layer2_mu = nn.Linear(hidden_dim, z_dim)
self.enc_layer2_logvar = nn.Linear(hidden_dim, z_dim)
# Define capas de decoder
self.dec_layer1 = nn.Linear(z_dim, hidden_dim)
self.dec_layer2 = nn.Linear(hidden_dim, x_dim)
def encoder(self, x):
x = F.relu(self.enc_layer1(x))
mu = self.enc_layer2_mu(x)
logVar = self.enc_layer2_logvar(x)
return mu, logVar
def reparameterize(self, mu, logvar):
std = torch.exp(logvar/2)
eps = torch.randn_like(std)
z = mu + std * eps
return z
def decoder(self, z):
output = F.relu(self.dec_layer1(z))
output = torch.tanh(self.dec_layer2(output))
return output
def forward(self, x):
mu, logvar = self.encoder(x)
z = self.reparameterize(mu, logvar)
output = self.decoder(z)
return output, z, mu, logvar
# Define la función de costo
def loss_function(output, x, mu, logvar):
batch_size = x.size(0)
recon_loss = F.mse_loss(output, x, reduction='sum') / batch_size
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) / batch_size
total_loss = recon_loss + 1.5 * kl_loss
return total_loss, recon_loss, 1.5 * kl_loss
learning_rate=1e-3
batch_size=128
num_epochs=15
hidden_dim=256
latent_dim=20
# Seleccionamos dispositivo en donde entrenar
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
x_dim = trainset[0][0].shape[0] # 784 for MNIST
# Definimos el modelo
model = VAE(x_dim=x_dim, hidden_dim=hidden_dim, z_dim=latent_dim)
model.to(device)
# Definimos el optimizador
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Entrena el modelo
for epoch in range(num_epochs):
epoch_recon_loss = 0
epoch_kl_loss = 0
for batch in trainloader:
# Pone los gradientes a cero
optimizer.zero_grad()
# Obtiene el batch de datos y lo mueve al dispositivo
x = batch[0].view(batch[0].size(0), -1) # Aplana si es necesario
x = x.to(device)
# Paso hacia adelante
output, z, mu, logvar = model(x)
# Calcula la pérdida
total_loss, recon_loss, kl_loss = loss_function(output, x, mu, logvar)
# Paso hacia atrás
total_loss.backward()
# Actualiza los parámetros
optimizer.step()
# Añade las pérdidas del batch a las pérdidas de la época
epoch_recon_loss += recon_loss.item()
epoch_kl_loss += kl_loss.item()
# Imprime las pérdidas de la época
avg_recon = epoch_recon_loss / len(trainloader)
avg_kl = epoch_kl_loss / len(trainloader)
print(f"Epoch {epoch+1}/{num_epochs}, Recon Loss: {avg_recon:.4f}, KL Loss: {avg_kl:.4f}, Total: {avg_recon + avg_kl:.4f}")
# Loop de evaluación: evalúa el modelo en el conjunto de prueba
print("\n--- Prueba en Conjunto de Prueba ---")
model.eval()
test_recon_loss = 0
test_kl_loss = 0
with torch.no_grad():
for batch in testloader:
x = batch[0].view(batch[0].size(0), -1)
x = x.to(device)
output, z, mu, logvar = model(x)
total_loss, recon_loss, kl_loss = loss_function(output, x, mu, logvar)
test_recon_loss += recon_loss.item()
test_kl_loss += kl_loss.item()
test_recon_avg = test_recon_loss / len(testloader)
test_kl_avg = test_kl_loss / len(testloader)
print(f"Test Recon Loss: {test_recon_avg:.4f}, Test KL Loss: {test_kl_avg:.4f}, Total: {test_recon_avg + test_kl_avg:.4f}")
# Genera nuevas imágenes muestreando del espacio latente
print("\n--- Generando Nuevas Imágenes ---")
model.eval()
with torch.no_grad():
# Muestrea de la distribución normal estándar en el espacio latente
z_samples = torch.randn(16, latent_dim)
z_samples = z_samples.to(device)
generated_images = model.decoder(z_samples)
# Reformatea a [batch_size, 1, 28, 28] para visualización
generated_images = generated_images.view(-1, 1, 28, 28)
# Visualiza las imágenes generadas
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
fig.suptitle("Generated Images from VAE", fontsize=14)
for idx, ax in enumerate(axes.flat):
# Desnormaliza: las imágenes están normalizadas con media=0.5, std=0.5
# desnormalizado = (normalizado * std) + media = (normalizado * 0.5) + 0.5
img = generated_images[idx].squeeze().cpu().numpy()
img = (img * 0.5) + 0.5 # Desnormaliza
img = np.clip(img, 0, 1) # Recorta a [0, 1]
ax.imshow(img, cmap='gray')
ax.axis('off')
plt.tight_layout()
plt.show()
# Reconstruye muestras de prueba para comparar original vs reconstruido
print("\n--- Reconstruyendo Muestras de Prueba ---")
model.eval()
with torch.no_grad():
# Obtiene un lote del conjunto de prueba
test_batch = next(iter(testloader))
x_test = test_batch[0].view(test_batch[0].size(0), -1)[:16] # Toma las primeras 16 muestras
x_test = x_test.to(device)
# Reconstruye
reconstructed, _, _, _ = model(x_test)
# Reformatea a [batch_size, 1, 28, 28] para visualización
x_test_img = x_test.view(-1, 1, 28, 28)
reconstructed_img = reconstructed.view(-1, 1, 28, 28)
# Visualiza original vs reconstruido
fig, axes = plt.subplots(4, 8, figsize=(14, 7))
fig.suptitle("Original vs Reconstructed Images", fontsize=14)
for idx in range(16):
# Original
img_orig = x_test_img[idx].squeeze().cpu().numpy()
img_orig = (img_orig * 0.5) + 0.5
img_orig = np.clip(img_orig, 0, 1)
axes[idx // 4, 2 * (idx % 4)].imshow(img_orig, cmap='gray')
axes[idx // 4, 2 * (idx % 4)].set_title("Original", fontsize=9)
axes[idx // 4, 2 * (idx % 4)].axis('off')
# Reconstruido
img_recon = reconstructed_img[idx].squeeze().cpu().numpy()
img_recon = (img_recon * 0.5) + 0.5
img_recon = np.clip(img_recon, 0, 1)
axes[idx // 4, 2 * (idx % 4) + 1].imshow(img_recon, cmap='gray')
axes[idx // 4, 2 * (idx % 4) + 1].set_title("Reconstruido", fontsize=9)
axes[idx // 4, 2 * (idx % 4) + 1].axis('off')
plt.tight_layout()
plt.show()
4.5. Red generativa adversa (GAN)#
La Red Generativa Adversa (GAN, del inglés Generative Adversarial Network) fue introducida por primera vez en 2014 por Ian J. Goodfellow [4]. Estas redes están compuestas por dos partes o sub-redes: un generador y un discriminador. El generador usualmente muestrea ruido de una distribución normal o gaussiana y luego prodce un dato falso a partir del ruido que debiera asemejarse a los datos verdaderos. El generador genera o crea casos falsos a partir de ruido gaussiano. Por otro lado, el discriminador trata de adivinar si el caso falso generador por el generador proviene de la base de datos o si es falso (proveniente del generador). Actúa como un juez frente a un caso que viene del generador, sin saber que si ese caso vino del generador o de la base de datos. Si el generador engaña al discriminador, es decir si el discriminador es incapaz de distinguir el caso generado por el generador de uno proveniente de los datos observados, entonces el generador está creando buenas muestras a partir de ruido gaussiano! Por lo tanto podemos entrenar ambas redes de manera tal que compitan entre ellas: que el generador intente engañar al discriminador y que el discriminador intente discriminar casos falsos de los verdaderos. A este tipo de entrenamiento se le suele llamar entrenamiento adversarial. El entrenamiento se cortará cuando el discriminador ya no pueda predecir si un caso generador por el generador proviene o no de la base de datos. El esquema de la arquitectura se presenta en la siguiente figura [5]:

Aquí podemos observar el espacio latente de baja dimensión en donde se genera ruido gaussiano. Este ruido se alimenta a la red generadora \(G\) y ésta crea una caso falso. Como las redes generativas se usan mucho para generar imágenes, este ejemplo muestra a un caso de nuestros datos como una imágen, pero se puede generar cualquier tipo de dato. También se muestra por lo tanto el conjunto de datos como el espacio de alta dimensionalidad de donde provienen los casos verdaderos. Luego ambos son alimentados a la red discriminadora \(D\), que toma la decisión si puede determinar que ambas imágenes vienen de distinta distribución (imágenes verdaderas o imágenes falsas).
Podemos pensar a una GAN como una competencia minimax, en donde el generador trata de minimizar sus chances de ser atrapado generando casos falsos mientras que el discriminador trata de maximizar sus chances de encontrar un caso falso. Esto se puede escribir matemáticamente
La función de costo acá se asemeja bastante a la función de costo llamada entropía cruzada binaria (BCE, del inglés Binary Cross Entropy), dada por
en donde \(Y\) representa la etqueta verdadera para el caso \(i\), \(\hat Y\) la predicción del discriminador y \(n\) el número de muestras en el conjunto de datos o el batch. La función de costo para un GAN se deriva de la BCE. Entendamos como funciona, viendo los casos límites. En una clasificación binaria (verdadero o falso) \(Y_i\in[0,1]\). Si \(Y_i=1\) el segundo término se anula, mientras que si \(Y_i=0\) el primero se anula. Luego, si el valor predicho \(\hat Y_i=1\) (verdadero) cuando \(Y_i=1\), el logaritmo anula el primer término y como el segundo se anula, esto no contribuye a la función de costo (caso ideal, ya que clasificó correctamente). Con un razonamiento análogo se puede ver que si \(Y_i=0\) y \(\hat Y_i=0\) entonces tampoco contribuye a la función de costo. Cualuier otro valor de predicción hará que al menos algún término sume al costo total. En el caso que le erra completamente, el término logaritmo hace que explote la función de costo y lo penaliza fuertemente.
Ahora volviendo al análisis de la función de costo para GAN, como se tiene que computar sobre muchos datos, utilizamos la expresión para los valores esperados para representar el promedio sobre la distribución de los datos. Como el discriminador intenta maximizar la función de costo clasificando los casos reales en reales y los falsos como falsos, debe empujar \(D(x)\approx1\) para muestras reales \(x\) mientras que debe empujar \(D(G(x))\approx 0\) para muestras falsas \(G(z)\), donde \(z \sim \mathcal N(0,\mathbb I^M)\), con \(M\) la dimensión del espacio latente donde se muestra el ruido gaussiano. De la misma manera, \(G\) minimiza la función de costo sólo empujando \(D(G(z))\approx 1\) para casos falsos, ya que el generador no ve los casos reales \(x\).
4.6. Mezcla de densidades Gaussianas (MDN)#
En una red de mezcla de densidades gaussianas (MDN del inglés, Mixture Density Network) se aproxima a la densidad de probabilidad de una variable \(t\) condicionada a un vector \(\vec{x}\), \(p(t|\vec{x})\) [6]. La idea fue propuesta por Christopher M. Bishop en su paper en 1994, [7], en donde dice textualmente “Why settle for one guess when you can have a whole bunch of them” (cuya traducción podría ser algo como: por qué quedarse con una estimación si podemos generar un montón de estimaciones posibles).
En este tipo de modelo, la densidad de probabilidad condicional está representada por una combinación lineal de funciones de kernel, típicamente funciones Gaussianas (aunque podrían ser otras). Es decir,
en donde \(\alpha_i(x)\) son los coeficientes que mezclan las densidades Gaussianas, determinando cuánto peso recibe cada componente \(\phi_i(t|x)\) para este modelo. En el caso de la mezcla de densidades gaussianas, estas componentes se pueden escribir como
siendo unívocamente definidas por sus parámetros: media \(\mu_i(x)\) y varianza \(\sigma_i^2\). \(c\) usualmente es 2.
De esta manera, podemos estimar la probabilidad condicional \(p(t|\vec{x})\) siempre que podamos estimar \(\alpha_i\), \(\mu_i\) y \(\phi_i\) para todo \(i=1\cdots,N\), donde \(N\) es el número de densidades gaussianas del modelo. Teniendo esto en cuenta, podríamos plantear una red neuronal tipo perceptrón múltiple, cuyas entradas corresponden al vector \(\vec{x}\) y cuya salida corresponde a los valores de \(\alpha_i\), \(\mu_i\) y \(\phi_i\), a partir de los cuáles podemos plantear la mezcla gaussiana y estimar la probabilidad para \(t\) dados los \(\vec{x}\). Esta idea se resume en la siguiente figura:

Los coeficientes que mezclan las densidades gaussianas, \(\alpha_i\), son cruciales ya que balancean la influencia de cada componente. Por ende, están normalizados, es decir que su suma es igual a 1 y esto se impone de manera sencilla mediante una función Softmax de la forma
en donde \(z_i^\alpha\) es la salida de la red neuronal que va a estimar el valor de los coeficientes de mezcla \(\alpha\). Lo mismo podemos hacer para el desvío estándar \(\sigma_i\) que debe ser positivo. En vez de permitir que la red estime \(\sigma_i\), hacemos que estime \(z_i^\sigma\) y que luego obtengamos el desvío estándar de manera sencilla mediante
Vemos en estos casos como restringimos la posibilidad de \(\sigma_i\) a valores positivos únicamente mediante una restricción dura o hard constraint.
El secreto está en cómo entrenar la red para que la probabilidad sea la que se observa en el conjunto de datos. Aquí es donde entra la maximización de la verosimilitud.
La verosimilitud de nuetros datos bajo el modelo MDN es el producto de las probabilidades asignadas a cada dato puntual. Es decir, es
en donde tenemos \(Q\) datos. Es decir, acá estamos calculando la probabilidad que hayamos medido los datos que medimos dado nuestro modelo de mezcla gaussiana. Podríamos tratar de maximizar esta verosimilitud, pero por cuestiones numéricas conviene hacer dos cosas. Por un lado, como el logaritmo es una función monótonamente creciente, maximizar una función \(f(x)\) es lo mismo que maximizar \(\ln f(x)\), es decir el máximo sigue estando en el mismo lugar. Para simplificar la productoria, tomamos el logaritmo de esta función
Por otro lado, los algoritmos de optimización generalmente están acostumbrados a minimizar funciones de costo, por ende podemos tomar el negativo del logaritmo de la función anterior como nuestra función de costo. Si remplazamos la expresión para \(\ln p(t^q | \vec{x}^q)\) nos queda que queremos optimizar
4.6.1. Ejemplo: Predicción de la sensación térmica#
Supongamos que contamos con la siguiente base de datos
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pandego/mdn-playground/refs/heads/main/data/01_raw/weather_dataset/weather_dataset_example.csv', delimiter=";")
print(data.shape)
data.head()
en donde contamos con 96453 mediciones de 7 variables: temperature (temperatura), apparent_temperature (sensación térmica), humidity (humedad), wind_speed, (velocidad de viento) wind_bearing (dirección del viento), visibility (visibilidad), pressure (presión). Queremos predecir la sensación térmica dada el resto de las variables (6 variables). Podríamos plantear un problema de regresión, pero también podríamos plantear una Mezcla de densidades gaussianas (MDN) para predecir la probabilidad de sensación térmica dadas las demás variables. Implementemos en python el entrenamiento de una MDN. Para esto, primero vamos a estandarizar los datos utilizando y luego dividir al conjunto de datos en entrenamiento (70%), validación (20%) y prueba (10%) utilizando las funcionalidades StandardScaler y train_test_split de scikit-learn.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
p_entrenamiento = 0.7
p_validacion = 0.2
p_prueba = 1 - p_entrenamiento - p_validacion
X = data.drop(columns=['apparent_temperature']).values
y = data['apparent_temperature'].values
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_temp, y_train, y_temp = train_test_split(X, y, train_size=p_entrenamiento, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, train_size=p_validacion/(p_validacion + p_prueba), random_state=42)
Luego, para utilizar una base de datos customizada en PyTorch, debemos implementar una clase que hereda de torch.utils.data.Dataset de la siguiente manera:
import torch
from torch.utils.data import Dataset
class DatasetTemperatura(Dataset):
def __init__(self, X, y):
self.x = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.float32)
def __len__(self):
return len(self.x)
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
train_dataset = DatasetTemperatura(X_train, y_train)
val_dataset = DatasetTemperatura(X_val, y_val)
test_dataset = DatasetTemperatura(X_test, y_test)
print(f'Tamaño del conjunto de entrenamiento: {len(train_dataset)}')
print(f'Tamaño del conjunto de validación: {len(val_dataset)}')
print(f'Tamaño del conjunto de prueba: {len(test_dataset)}')
Además, crearemos los DataLoaders que permiten luego hacer batches de 64 casos y aleatorización
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=64, shuffle=False)
test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=False)
Aquí viene la implementación de nuestro modelo MDN como una clase de PyTorch, siguiendo la lógica presentada al comienzo de esta sección:
import torch.nn as nn
import torch.nn.functional as F
class MDN(nn.Module):
def __init__(self, dim_entrada, dim_salida, num_ocultas, num_mezclas):
super(MDN, self).__init__()
self.capa_oculta = nn.Sequential(
nn.Linear(dim_entrada, num_ocultas),
nn.Tanh(),
nn.Linear(num_ocultas, num_ocultas),
nn.Tanh(),
)
self.z_alfa = nn.Linear(num_ocultas, num_mezclas)
self.z_mu = nn.Linear(num_ocultas, num_mezclas * dim_salida)
self.z_sigma = nn.Linear(num_ocultas, num_mezclas * dim_salida)
self.num_mezclas = num_mezclas
self.dim_salida = dim_salida
def forward(self, x):
capa_oculta = self.capa_oculta(x)
alfa = F.softmax(self.z_alfa(capa_oculta), dim=1)
sigma = torch.exp(self.z_sigma(capa_oculta)).view(-1, self.num_mezclas, self.dim_salida)
mu = self.z_mu(capa_oculta).view(-1, self.num_mezclas, self.dim_salida)
return alfa, sigma, mu
Para poder entrenar este modelo, hemos visto que debemos minimizar el negativo del logaritmo de la verosimilitud. Esta función de costo la podemos plantear de la siguiente manera:
def mdn_loss(alfa, sigma, mu, y, eps=1e-8):
m = torch.distributions.Normal(loc=mu, scale=sigma)
# Ensure y has shape [batch, num_mezclas, dim_salida] to match `mu`/`sigma` for broadcasting
y = y.view(-1, 1, 1).expand_as(mu)
prob = torch.exp(m.log_prob(y))
prob_weighted = prob * alfa.unsqueeze(2)
prob_sum = torch.sum(prob_weighted, dim=1)
nll = -torch.log(torch.clamp(prob_sum, min=eps))
return torch.mean(nll)
Una vez definidos los datos, la función de costo y el modelo, podemos entrenar como hacemos usualmente. Podemos definir el número de épocas y si queremos entrenar utilizando una GPU.
num_epocas = 100
# Usar GPU si hay disponible
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
modelo = MDN(dim_entrada=6, dim_salida=1, num_ocultas=50, num_mezclas=3)
modelo.to(device)
optimizador = torch.optim.Adam(modelo.parameters(), lr=0.001)
for epoca in range(num_epocas):
modelo.train()
perdida_total = 0
for x_batch, y_batch in train_dataloader:
# Move batch to device
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
optimizador.zero_grad()
alfa, sigma, mu = modelo(x_batch)
perdida = mdn_loss(alfa, sigma, mu, y_batch)
perdida.backward()
optimizador.step()
perdida_total += perdida.item()
perdida_media = perdida_total / len(train_dataloader)
if (epoca + 1) % 10 == 0:
print(f'Época {epoca+1}/{num_epocas}, Pérdida: {perdida_media:.4f}')
modelo.eval()
perdida_val_total = 0
with torch.no_grad():
for x_val, y_val in val_dataloader:
x_val = x_val.to(device)
y_val = y_val.to(device)
alfa_val, sigma_val, mu_val = modelo(x_val)
perdida_val = mdn_loss(alfa_val, sigma_val, mu_val, y_val)
perdida_val_total += perdida_val.item()
perdida_val_media = perdida_val_total / len(val_dataloader)
print(f' Pérdida de validación: {perdida_val_media:.4f}')
modelo.train()
modelo.eval()
perdida_test_total = 0
with torch.no_grad():
for x_test, y_test in test_dataloader:
x_test = x_test.to(device)
y_test = y_test.to(device)
alfa_test, sigma_test, mu_test = modelo(x_test)
perdida_test = mdn_loss(alfa_test, sigma_test, mu_test, y_test)
perdida_test_total += perdida_test.item()
perdida_test_media = perdida_test_total / len(test_dataloader)
print(f'Pérdida en el conjunto de prueba: {perdida_test_media:.4f}')
Vemos que la red aprende a minimizar el negativo de la log-verosimilitud y que funciona bien en el conjunto de datos de prueba que nunca fue utilizado durante el entrenamiento.
Finalmente, puede ser un poco difícil muestrear de un MDN ya que primero hay que elegir de cuál de las densidades gaussianas se muestreará (utilizando las constantes normalizadas como pesos) y luego hay que muestrear la densidad gaussiana con los valores de mu y sigma correspondiente al alfa seleccionado. La siguiente función realiza lo mencionado, teniendo en cuenta que \(B\) es el tamaño del batch y \(K\) la cantidad de Gaussianas.
def mdn_sample(alfa, sigma, mu):
"""
alfa: [B, K]
sigma, mu: [B, K, 1]
Devuelve una muestra y_hat: [B]
"""
B, K = alfa.shape
cat = torch.distributions.Categorical(probs=alfa)
k_idx = cat.sample() # [B]
# Seleccionar mu y sigma de la componente elegida
b_idx = torch.arange(B, device=alfa.device)
mu_k = mu[b_idx, k_idx, 0] # [B]
sigma_k = sigma[b_idx, k_idx, 0] # [B]
normal = torch.distributions.Normal(mu_k, sigma_k)
y_hat = normal.sample() # [B]
return y_hat
Una vez implementada la función de muestreo de nuestra nueva probabilidad condicional estimada, podemos ver el resultado de la predicción con respecto a los valores medidos en el conjunto de prueba. Lo vamos a ver mediante un histograma de ambas distribuciones (medida y muestreada) como así también un gŕafico de valores de sensación térmica medidos vs. predichos.
import matplotlib.pyplot as plt
import numpy as np
modelo.eval()
y_true_all = []
y_pred_sample_all = []
y_pred_mean_all = []
with torch.no_grad():
for x_batch, y_batch in test_dataloader:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
alfa, sigma, mu = modelo(x_batch)
y_pred_s = mdn_sample(alfa, sigma, mu)
y_pred_m = (alfa.unsqueeze(2) * mu).sum(dim=1)[:, 0]
y_true_all.append(y_batch.detach().cpu().numpy())
y_pred_sample_all.append(y_pred_s.detach().cpu().numpy())
y_pred_mean_all.append(y_pred_m.detach().cpu().numpy())
y_true_all = np.concatenate(y_true_all).reshape(-1)
y_pred_sample_all = np.concatenate(y_pred_sample_all).reshape(-1)
y_pred_mean_all = np.concatenate(y_pred_mean_all).reshape(-1)
plt.figure()
plt.hist(y_true_all, bins=30, alpha=0.6, density=True, label="Medido")
plt.hist(y_pred_sample_all, bins=30, alpha=0.6, density=True, label="Predicción")
plt.xlabel("Sensación térmica (apparent_temperature, °C)")
plt.ylabel("Densidad")
plt.title("Distribución: Medido vs Predicho")
plt.legend()
plt.show()
plt.figure()
plt.scatter(y_true_all, y_pred_mean_all, alpha=0.6)
mn = min(y_true_all.min(), y_pred_mean_all.min())
mx = max(y_true_all.max(), y_pred_mean_all.max())
plt.plot([mn, mx], [mn, mx], c='red')
plt.xlabel("Medido (°C)")
plt.ylabel("Predicho (media de mezcla, °C)")
plt.title("Medido vs Predicho")
plt.show()
Vemos que a pesar de una subestimación de la sensación térmica por encima de 30\(^\circ\)C y por debajo de -20\(^\circ\)C, las predicciones concuerdan muy bien con los valores medidos y que la distribución de valores muestrada sigue la forma de la distribución medida.
4.7. Flujos normalizadores (NF)#
Los Flujos normalizadores (NF, del inglés Normalizing Flows) son modelos cuyo objetivo es aprender una distribución de probabilidad. Estos modelos de redes neuronales profundas transforman una función de distribución base \(p_Z\) en una distribución objetivo \(p_Y\) mediante una serie de transformaciones que llamaremos flujos. La idea principal está en utilizar una secuencia de mapeos diferenciables e invertibles como capas de una red neuronal que se puede entrenar. Como las transformaciones son invertibles, podemos tratar de aprender un conjunto de transformaciones que llevan la distribución del conjunto de datos de interés a una distribución simple (generalmente utilizaremos una gaussiana multidimensional) y luego utilizar la inversa y un muestreo de la distribución simple (fácil de muestrear), para generar nuevos datos que siguen distribución original. Para esto, primero nos centraremos en entender cómo se modifica una distribución de probabilidad bajo una transformación invertible y diferenciable.
4.7.1. Transformando distribuciones de probabilidad#
Supongamos una transformación invertible \(g: \mathbb R^D \rightarrow \mathbb R^D\) y su inversa \(f = g^{-1}\). Tenemos por lo tanto \(\vec y=g(\vec z)\) y \(\vec z=f(\vec y)\). La densidad de probabilidad \(p_Y(\vec y)\) se puede obtener a partir de la densidad de probabilidad de \(Z\). Para esto, partimos de una de las definiciones de distribución de probabilidad, que es que la integral sobre todo el espacio de la densidad de probabilidad debe ser 1 independientemente de la transformación aplicada.
de lo que, utilizando un cambio de variable \(\vec z=f(\vec y)\) y comparando los integrandos, obtenemos que
en donde \(\frac{\partial f(\vec y)}{\partial \vec y}\) es el Jacobiano de \(f\), y la magnitud de su determinante provee el escaleo de \(y\) debido a \(f\). Pongamos un ejemplo 1-dimensional para ayudar a la comprensión y recordar siempre que es necesario el escaleo por Jacobiano de la transformación. Supongamos entonces que \(D=1\), y que \(g(z)=2z+1=y\). Esta transformación es invertible, \(f(y)=g^{-1}(y)=(y-1)/2\), y su derivada es \(1/2\). Cuando se escalea, se modifica el volumen de la densidad de probabilidad, como se muestra en la siguiente figura. Supongamos que \(z\) tiene una distribución de probabilidad uniforme en el intervalo \((0,1)\), entonces \(g(z)\) pasa a tener una distribución de probabilidad uniforme en el intervalo \((1,3)\) y para que se conserve la probabilidad total (que el área sea 1), como el rango de la variable se duplicó, la densidad de probabilidad se debe reducir a la mitad.
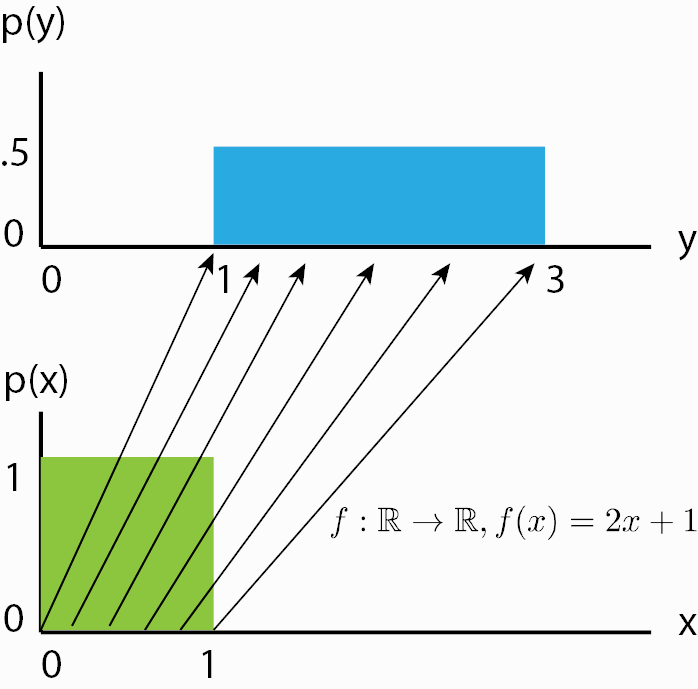
Este cambio de densidad de probabilidad es lo que se representa con el jacobiano de la transformación en la ecuación anterior y lo que permite que sigamos teniendo una distribución de probabilidad válida luego de transformar la variable.
Como generalmente estaremos trabajando con la log-verosimilityd como función de costo, entonces podemos escribir la ecuación de la transformación con el logaritmo aplicado,
Cuando \(f\) es sencilla, como en este caso, resulta fácil calcular la inversa. Pero por ahí la transformación que la distribución de probabilidad \(p_Z\) necesita para llegar a la distribución de probabilidad objetivo de nuestros datos \(p_X\) puede ser extremadamente compleja. En estos casos, más que buscar una sóla transformación que lleve de \(p_Z\) a \(p_X\), conviene empezar a componer funciones invertibles simples, ya que la composición de dos funciones invertibles \(f_1 \circ f_2\) es también una función invertible (\((f_1 \circ f_2)^{-1}=f_1^{-1}\circ f_2^{-1}\)). De esta manera, utilizando varias funciones invertibles aprendibles, un normalizador de flujo intenta transformar la distribución \(p_Z(z)\) gradualmente hacia una distribución más compleja, la cuál finalmente debiera ser la de los datos \(p_X(x)\). La visualización siguiente (obtenida del artículo de Lilian Weng) esquematiza la idea central en un normalizador de flujo.
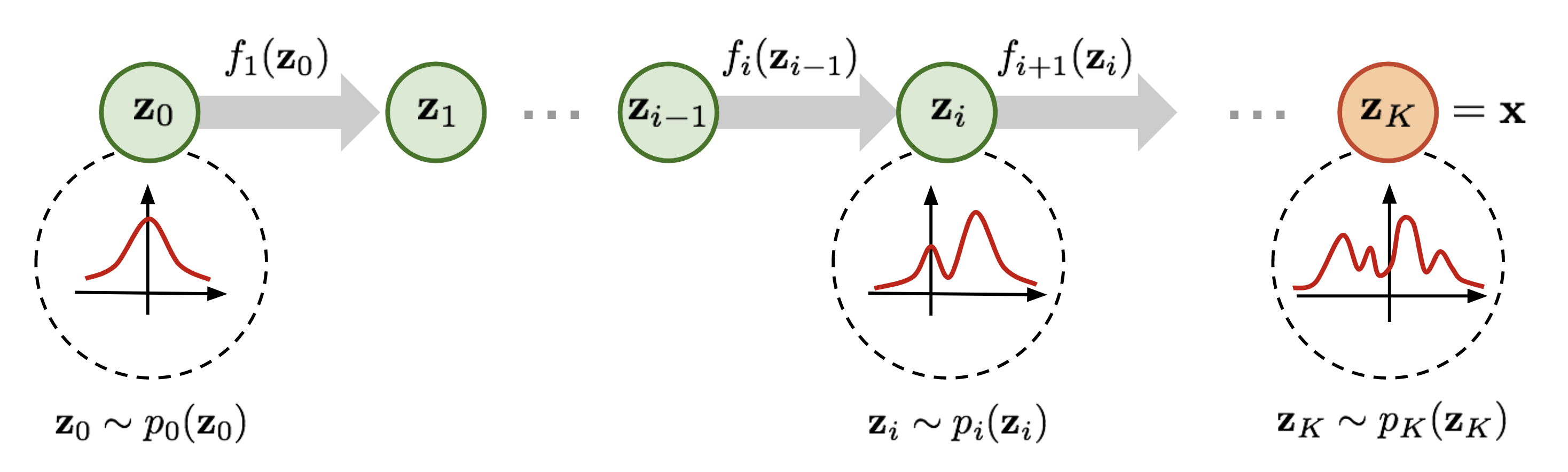
Teniendo en cuenta esta notación vemos que
A su vez, \(\vec z_{i}\) resulta de aplicar la transformación \(f_i\) a \(\vec z_{i-1}\), i.e.
por lo que
Aplicando la ecuación de cambio de variable para las distribuciones de probabilidad que vimos anteriormente, llegamos a que
Ahora, el teorema de la función inversa nos permite ver que si \(y=f(x)\) y \(z=f^-1(y)\), entonces \(\frac{\partial f^{-1}(y)}{\partial y} = \frac{\partial x}{\partial y} = \left(\frac{\partial y}{\partial x}\right)^{-1} = \left(\frac{\partial f(x)}{\partial x}\right)^{-1}\) (fácil de ver en 1D, válido para más dimensiones). Con esto, entonces \(\left |\det \frac{\partial f_{i}^{-1}(\vec z_i)}{\partial \vec z_i}\right|=\left |\det \frac{\partial f_{i}(\vec z_{i-1})}{\partial \vec z_{i-1}}\right|^{-1}\) (en donde además se tuvo en cuenta que \(\det (M^{-1}) = (\det (M))^{-1}\), que es fácil de probar ya que \(\det(M) \det(M^{-1}) = \det (M \cdot M^{-1})=\det (I) = 1\)). Con esto, finalmente llegamos a la ecuación que utilizaremos a continuación para obtener como cambia la distribución de \(\vec z_i\) al transformarse desde \(z_{i-1}\) mediante \(f_i\) que es
cuya versión logarítmica se puede escribir como
Aplicando \(K\) transformaciones, podemos escribir
El camino recorrido por las variables aleatorias \(\vec z_i = f_i(\vec z_{i-1})\) es el que da la idea de un flujo de probabilidad y la cadena total formada por las transformaciones sucesivas se llama normalizador de flujo.
El muestreo de estas transformaciones resulta super conveniente y sencillo. Se muestrea un vector aleatorio de \(\vec z_0 \sim p_0\), la cuál normalmente es una distribución Gaussiana multivariada (fácil de muestrear). Luego se transforma mediante \(\vec x=G(\vec z_0)=f_K \circ f_{K-1} \circ \cdots \circ f_1(\vec z_0)\) y su probabilidad se calcula transformando \(p_0(\vec z_0)\) a \(p_X(\vec x)\) como explicado anteriormente.
4.7.2. Inclusión de redes neuronales#
Hasta el momento sólo vimos que podemos transformar una distribución de probabilidad en otra si aplicamos una serie de transformaciones simples que sean invertibles y diferenciables. La simplicidad viene dada por la capacidad de diferenciarla e invertirla que tengamos y de qué tan simple resulta calcular el Jacobiano de la transformación. En vez de estar eligiendo y diseñando qué funciones utilizar, resulta conveniente directamente plantear redes neuronales como las funciones \(f_i\), ya que tenemos la capacidad de derivarlas gracias a la auto-diferenciación y diseñarlas de manera tal que cumpla con la invertibilidad y la facilidad de calcular el Jacobiano. Para ser invertibles, resulta necesario que es espacio latente de cada red neuronal (es decir, la dimensionalidad de salida) sea de la misma dimensión que el vector de entrada. Una vez que tenemos las funciones \(f_i\) parametrizadas por los parámetros de redes neuronales, podemos entrenarlas utilizando la maximización de la log-verosimilitud, utilizando la ecuación que obtuvimos antes para \(\log p_X(\vec x)\).
Como ejemplo, vamos a explorar un modelo de NF que se llama Real NVP (real-valued non-volume preserving). La base de este modelo es una capa llamada capa de acoplamiento afin (Affine Coupling Layer). Cuando se utiliza este tipo de capa en la dirección hacia delante (forward pass) se divide al vector de entrada \(\vec x\) en dos partes, una de dimensión \(d\) y otra de dimensión \(D-d\), siendo \(D\) la dimensión de \(\vec{x}\). Una de las dos partes no se modifica en absoluto y pasa tal cuál entra hacia la salida \(\vec y\) de la capa. Si suponemos que es la primer parte de dimensión \(d\) la que pasa sin modificación por la capa, entonces podemos decir que los primero \(d\) elementos de \(\vec y\) son los primeros \(d\) elementos de \(\vec x\), i.e. \(\vec y_{1:d} = \vec x_{1:d}\). Los elementos restantes \(\vec x_{(d+1):D}\) serán transformados mediante un escaleo \(s\) y un corrimiento \(t\) que serán función de la primer parte del vector de entrada \(\vec x_{1:d}\) y se aprenderán mediante perceptrones múltiples, donde
La exponencial aparece porque se predice utilizando la log-verosimilitud y estabiliza el entrenamiento. Ahora, esta función ¿cumple con lo que necesitábamos para tener una transformación útil para un flujo normalizador? Necesitabamos que sea invertible. Invertir esta operación resulta posible gracias a que dividimos el vector de entrada en dos partes, tenemos esa “memoria” de la entrada en la salida y las transformaciones dependen de esa memoria. Como escalear (multiplicar por una constante) y realizar un desplazamiento (sumar una constante) son transformaciones invertibles, entonces podemos a partir de \(\vec y\) calcular la constante multiplicativa, la constante aditiva con los dos perceptrones múltiples \(s(\vec y_{1:d})\) y \(t(\vec y_{1:d})\), restar la constante aditiva y dividir por la multiplicativa y así obtener \(\vec x_{(d+1):D} = (\vec y_{(d+1):D} - t(\vec{y_{1:d}})) \odot \exp (-s(\vec y_{1:d}))\). La primer parte del vector de entrada queda exactamente igual a la primera parte del vector de salida en la operación inversa.
Por otro lado, el cálculo del determinante del Jacobiano no pareciera ser fácil ya que tenemos un vector de entrada de dimensión \(D\), por lo que deberíamos calcular \(D^2\) elementos del Jacobiano, lo que sería extremadamente costoso de calcular en cada iteración del entrenamiento. Debido a la estructura que planteamos para la capa de acoplamiento afin, el Jacobiano tendrá la forma
Esta matriz es una matriz triangular inferior, y por lo tanto el determinante de este tipo de matriz es el producto de los elementos diagonales! Por lo tanto, el determinante se simplifica de manera grata a
que como luego utilizamos el logaritmo del determinante del Jacobiano, nos queda simplemente la sumatoria de los factores de escaleo producidos por la red. Así, finalmente el logaritmo de la verosimilitud queda escrito como
Finalmente, el modelo de NF Real NVP no es más que la aplicación sucesiva reiterada de estas capas de acoplamiento afin. Ahora, si pensamos que siempre estamos dejando pasar exactamente igual la primer parte del vector de entrada en cada capa, entonces al final tendremos siempre esa parte del vector intacto a la salida del modelo Real NVP. Como no queremos esto, lo que los autores hacen es alternar en cada capa cuál parte del vector pasa y cual se modifica mediante la transformación de acoplamiento afin.
Veremos un ejemplo a continuación para entenderlo mejor.
4.8. Ejemplo: Aprendiendo Gaussianas#
Primero generamos un conjunto de datos que proviene de una mezcla de densidades Gaussianas.
import numpy as np
class GaussianMixture:
def __init__(self, parameters):
self.parameters = parameters
self.distributions = [
{
'mean': np.array(dist['mean']),
'std': np.array(dist['std']),
'cov': np.diag(np.array(dist['std']) ** 2)
}
for dist in parameters
]
def sample(self, num_samples):
samples = []
num_distributions = len(self.distributions)
for _ in range(num_samples):
idx = np.random.randint(num_distributions) # Choose a random Gaussian
dist = self.distributions[idx]
sample = np.random.multivariate_normal(mean=dist['mean'], cov=dist['cov'])
samples.append(sample)
return np.array(samples)
def likelihood(self, points):
likelihoods = np.zeros(points.shape[0])
for dist in self.distributions:
mean = dist['mean']
cov = dist['cov']
inv_cov = np.linalg.inv(cov)
det_cov = np.linalg.det(cov)
# Multivariate Gaussian PDF
factor = 1 / (2 * np.pi * np.sqrt(det_cov))
diff = points - mean
exponents = -0.5 * np.sum(diff @ inv_cov * diff, axis=1)
likelihoods += factor * np.exp(exponents)
return likelihoods
La clase GaussianMixture (GM) se puede utilizar para muestrear de múltiples distribuciones Gaussianas 2D como a su vez para evaluar la probabilidad en diferentes posiciones. Visualicemos como se distribuyen las muestras y cómo es la densidad de probabilidad generada.
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_theme(style="ticks")
def plot_gaussian_mixture(gm, samples, grid_size=100):
x_min, x_max = np.min(samples[:, 0]) - 1, np.max(samples[:, 0]) + 1
y_min, y_max = np.min(samples[:, 1]) - 1, np.max(samples[:, 1]) + 1
x = np.linspace(x_min, x_max, grid_size)
y = np.linspace(y_min, y_max, grid_size)
X, Y = np.meshgrid(x, y)
points = np.column_stack([X.ravel(), Y.ravel()])
densities = gm.likelihood(points).reshape(grid_size, grid_size)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
ax1 = axes[0]
ax1.scatter(samples[:, 0], samples[:, 1], s=10, alpha=0.7, color="blue")
ax1.set_title("Scatterplot", fontsize=16)
ax1.set_xlim(x_min, x_max)
ax1.set_ylim(y_min, y_max)
ax2 = axes[1]
contour = ax2.contourf(X, Y, densities, cmap="viridis", levels=50)
cbar = fig.colorbar(contour, ax=ax2)
cbar.set_label("Density", fontsize=14)
ax2.set_title("Density Plot", fontsize=16)
ax2.set_xlim(x_min, x_max)
ax2.set_ylim(y_min, y_max)
plt.tight_layout()
plt.show()
parameters = [
{"mean": [0, 0], "std": [1, 1]},
{"mean": [3, 2], "std": [0.5, 0.5]}
]
gm = GaussianMixture(parameters)
samples = gm.sample(1000)
plot_gaussian_mixture(gm, samples)
Utilizando esta distribución como punto de partida, la aprenderemos utilizando un Normalizador de Flujo simple, basado en un acoplamiento afin. Para esto, utilizaremos una red neuronal con tres capas y funciones de activación ReLU. El código a continuación provee la clase base RealNVP2D (NVP viene del inglés Neural volume preserving ya que preservan el volumen de la distribución)
import torch.nn as nn
class FCNN(nn.Module):
def __init__(self, input_dim, output_dim, hidden_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
return self.net(x)
class NVPBlock2D(nn.Module):
def __init__(self, dim_flow, hidden_dim=256, flip=False):
super().__init__()
self.dim_flow = dim_flow
self.hidden_dim = hidden_dim
self.flip = flip
self.f = FCNN((dim_flow // 2), dim_flow, hidden_dim)
def shift_and_log_scale_fn(self, x1):
s = self.f(x1)
shift, log_scale = torch.chunk(s, 2, dim=1)
return shift, log_scale
def forward(self, x, ldj=None):
d = self.dim_flow // 2
x1, x2 = x[:, :d], x[:, d:]
if self.flip:
x1, x2 = x2, x1
fcnn_input = x1
shift, log_scale = self.shift_and_log_scale_fn(fcnn_input)
y2 = x2 * torch.exp(log_scale) + shift
if self.flip:
x1, y2 = y2, x1
z = torch.cat([x1, y2], dim=-1)
if ldj is not None:
ldj = ldj + log_scale.sum(dim=-1)
return z, ldj
def inverse(self, z, ldj=None):
d = self.dim_flow // 2
y1, y2 = z[:, :d], z[:, d:]
if self.flip:
y1, y2 = y2, y1
fcnn_input = y1
shift, log_scale = self.shift_and_log_scale_fn(fcnn_input)
x2 = (y2 - shift) * torch.exp(-log_scale) # Apply inverse affine transformation
if self.flip:
y1, x2 = x2, y1
x = torch.cat([y1, x2], dim=-1)
if ldj is not None:
ldj = ldj - log_scale.sum(dim=-1)
return x, ldj
class RealNVP2D(nn.Module):
def __init__(self, dim_flow, steps=6, hidden_dim=256):
super().__init__()
self.flows = nn.ModuleList()
flip = False
for _ in range(steps):
self.flows.append(NVPBlock2D(dim_flow, hidden_dim, flip=flip))
flip = not flip
def forward(self, x, num_layers=None):
if num_layers is None:
num_layers = len(self.flows)
ldj = torch.zeros(x.shape[0], device=x.device)
for flow in self.flows[:num_layers]:
x, ldj = flow(x, ldj)
return x, ldj
def inverse(self, z, num_layers=None):
if num_layers is None:
num_layers = len(self.flows)
ldj = torch.zeros(z.shape[0], device=z.device)
for flow in list(reversed(self.flows[:num_layers])):
z, ldj = flow.inverse(z, ldj)
return z, ldj
Luego podemos generar el conjunto de datos y entrenar
import torch
from torch.utils.data import DataLoader, TensorDataset
def generate_2d_gaussian_mixture(num_samples, gm):
samples = gm.sample(num_samples)
return torch.tensor(samples, dtype=torch.float32)
def train_model(model, dataloader, optimizer, num_epochs=50, device="cuda"):
model.train()
model.to(device)
losses = []
for epoch in range(num_epochs):
epoch_loss = 0.0
for x in dataloader:
x = x[0].to(device)
optimizer.zero_grad()
z, ldj = model(x)
prior = (-0.5 * z ** 2).sum(-1) - 0.5 * torch.log(torch.tensor(2.0 * torch.pi))
loss = (-prior - ldj).mean()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dataloader)
losses.append(avg_loss)
print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {avg_loss:.4f}")
return losses
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
from sklearn.utils import shuffle
samples = generate_2d_gaussian_mixture(50000, gm)
samples = shuffle(samples.numpy())
dataset = TensorDataset(torch.tensor(samples, dtype=torch.float32))
dataloader = DataLoader(dataset, batch_size=128, shuffle=True)
dim_flow = 2
steps = 6
hidden_dim = 256
realnvp_model = RealNVP2D(dim_flow, steps, hidden_dim).to(device)
optimizer = torch.optim.Adam(realnvp_model.parameters(), lr=2e-4)
# Step 3: Train the model
num_epochs = 50
losses = train_model(realnvp_model, dataloader, optimizer, num_epochs=num_epochs, device=device)
y finalmente visualizar en cada capa como se está transformando la distribución de probabilidad desde una gaussiana bidimensional a la mezcla de densidades gaussianas.
import matplotlib.pyplot as plt
def get_angle_colors(positions):
angles = np.arctan2(positions[:, 1], positions[:, 0])
angles_deg = (np.degrees(angles) + 360) % 360
colors = np.zeros((len(positions), 3))
for i, angle in enumerate(angles_deg):
segment = int(angle / 120)
local_angle = angle - segment * 120 # angle within segment [0, 120]
if segment == 0:
colors[i] = [1 - local_angle/120, local_angle/120, 0]
elif segment == 1:
colors[i] = [0, 1 - local_angle/120, local_angle/120]
else:
colors[i] = [local_angle/120, 0, 1 - local_angle/120]
return colors
def visualize_progression_with_layers_and_likelihoods(model, grid_size=100, num_layers_max=6, num_samples=1000):
model.eval()
fig, axes = plt.subplots(2, num_layers_max + 1, figsize=(20, 8))
x = np.linspace(-5, 5, grid_size)
y = np.linspace(-5, 5, grid_size)
X, Y = np.meshgrid(x, y)
points = np.column_stack([X.ravel(), Y.ravel()])
points_tensor = torch.tensor(points, dtype=torch.float32).to(device)
for num_layers in range(num_layers_max + 1):
z = torch.randn(num_samples, model.flows[0].dim_flow).to(device)
c = get_angle_colors(z.detach().cpu().numpy())
with torch.no_grad():
samples, _ = model.inverse(z, num_layers=num_layers)
samples = samples.cpu().numpy()
scatter_ax = axes[0, num_layers]
scatter_ax.scatter(samples[:, 0], samples[:, 1], s=10, alpha=0.7, c=c)
scatter_ax.set_title(f"Layer: {num_layers}")
scatter_ax.set_xlim(-5, 5)
scatter_ax.set_ylim(-5, 5)
scatter_ax.set_xlabel("")
scatter_ax.set_ylabel("")
with torch.no_grad():
z, ldj = model(points_tensor, num_layers=num_layers)
prior = (-0.5 * z ** 2).sum(-1) - 0.5 * torch.log(torch.tensor(2.0 * torch.pi))
likelihoods = torch.exp(prior + ldj).cpu().numpy().reshape(grid_size, grid_size)
likelihood_ax = axes[1, num_layers]
contour = likelihood_ax.contourf(X, Y, likelihoods, levels=50, cmap="viridis")
likelihood_ax.set_xlim(-5, 5)
likelihood_ax.set_ylim(-5, 5)
likelihood_ax.set_xlabel("")
likelihood_ax.set_ylabel("")
plt.tight_layout()
plt.show()
visualize_progression_with_layers_and_likelihoods(realnvp_model, grid_size=100, num_layers_max=6, num_samples=1000)
Resulta interesante notar que la red neuronal no toma un camino muy intuitivo para llegar a la distribución objetivo. Se va transformando de manera bastante aleatoria hasta que logra encontrar algo que se asemeja a la distribución original. Como no hay constraints en las distribuciones intermedias, esto depende fuertemente de la inicialización aleatoria de los pesos de la red. Luego veremos cómo podemos hacer para sobrellevar este problema.
Wikipedia contributors. Jensen's inequality. 2026. URL: https://en.wikipedia.org/wiki/Jensen%27s_inequality.
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. 2022. URL: https://arxiv.org/abs/1312.6114, arXiv:1312.6114.
Mathew Bernstein. Variational autoencoders. 2023. URL: https://mbernste.github.io/posts/vae/.
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. 2014. URL: https://arxiv.org/abs/1406.2661, arXiv:1406.2661.
Ameh Emmanuel Sunday. The math behind generative adversarial networks explained intuitively. 2025. URL: https://medium.com/@amehsunday178/the-math-behind-generative-adversarial-networks-explained-intuitively-3509bafae04f.
Miguel Mirandas Dias. Predicting the unpredictable. 2014. URL: https://medium.com/data-science/predicting-the-unpredictable-905f634acc20.
Christopher M. Bishop. Mixture density networks. Copyright © 1994, Christopher M. Bishop. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (https://creativecommons.org/licenses/by-nc-nd/4.0/)., 1994. URL: https://publications.aston.ac.uk/id/eprint/373/.