1. Introducción a la inteligencia artificial y al aprendizaje profundo#
Diapositivas teórico: Semana_1.pdf
Notebook teórico-práctico: Semana01_intro_pytorch.ipynb
Guía de trabajo práctico: Guia_Semana_01_Fundamentos_Python_y_ML.ipynb
1.1. Introducción#
Hoy en día, la inteligencia artificial (IA) es un campo fértil con muchas aplicaciones prácticas y un área de investigación extremadamente activa. Se buscan soluciones de parte de softwares inteligentes para la automatización de rutinas de trabajo, para entender imágenes o comprender el habla, para hacer diagnósticos médicos, para asistir a la investigación científica básica, y mucho más.
Algunos éxitos tempranos de la IA se dieron en aplicaciones donde las computadoras o bien los modelos no requerían tener conocimiento acerca del mundo, sino más bien de una realidad acotada. Por ejemplo, en 1997 el modelo Deep Blue de IBM pudo vencer al campeón mundial de ajedrez del momento, Garry Kasparov. Este modelo se tuvo que entrenar en un espacio muy acotado de 64 casillas y 32 piezas que se pueden mover bajo determinadas reglas. Fue capaz de divisar estrategias de ajedrez basados en los movimientos del contrincante y fue un éxito rotundo del momento. Sin embargo, las reglas estaban bien definidas y la posibilidad de acciones en la realidad del ajedrez eran extremadamente acotadas.
Al parecer, tareas formales y abstractas que son desafiantes y difíciles para los seres humanos suelen ser las más fáciles para las computadoras. Desde hace tiempo que una IA puede ganarle al mejor jugador de ajedrez del mundo, pero tareas super sencillas para nosotros, como reconocer objetos o entender frases y poder hablar, han sido desafíos enormes para las computadoras y recién hace relativamente poco han podido empezar a resolver estas tareas con capacidades similares que los seres humanos.
Han habido intentos de codificar a fuerza bruta el conocimiento acerca del mundo en lenguajes formales de programación, donde luego la computadora puede razonar automáticamente acerca de las declaraciones en este lenguaje formal infiriendo mediante reglas lógica. Este abordaje a la IA se conoce como abordaje basado en el conocimiento [1], pero ninguno de estos proyectos ha resultado en éxitos mayores. Para los interesados, uno de los proyectos más famosos de esta índole fue Cyc [2], pero han habido claros contraejemplos de falta de entendimiento de las situaciones hipotéticas planteadas en el momento de inferencia.
Sin embargo, las dificultades que aparecieron ante este intento de codificar a fuerza bruta el conocimiento sugirieron que los sistemas de inteligencia artificial debían tener la habilidad de adquirir su propio conocimiento a partir de la identificación de patrones en datos crudos. A esta capacidad se la llamó Aprendizaje automático y con su introducción las computadoras fueron capaces de abordar problemas que involucraban conocimiento del mundo real y tomar decisiones que aparentaban subjetivas. Así aparecieron modelos de aprendizaje automático como la regresión logística, o naive Bayes, máquinas de soporte vectorial, árboles de decisión, entre tantos otros.
La performance de estos algoritmos simples de aprendizaje automático depende fuertemente de la representación de los datos con los cuáles son entrenados. Cada pieza de información que se le da de entrada al modelo para su entrenamiento se conoce como una característica o feature en inglés.
1.2. Aprendizaje automático#
El aprendizaje automático ha experimentado una evolución notable en las últimas décadas, transformándose de un campo de investigación teórico a una herramienta esencial en diversas disciplinas, incluida la física. Este progreso ha sido impulsado por avances en el poder computacional, la disponibilidad de grandes volúmenes de datos y el desarrollo de algoritmos más sofisticados. Dentro del aprendizaje automático, se distinguen tres paradigmas principales: el aprendizaje supervisado, el no supervisado y el aprendizaje por refuerzo, cada uno con sus propias características y aplicaciones.
El aprendizaje supervisado es quizás el más intuitivo de los tres paradigmas. En este enfoque, los modelos son entrenados utilizando un conjunto de datos etiquetados, donde cada entrada está asociada con una salida deseada. Este método se asemeja a un proceso de enseñanza tradicional, donde un “maestro” proporciona ejemplos correctos y el “estudiante” (el modelo) aprende a generalizar a partir de ellos. Históricamente, el aprendizaje supervisado ha sido fundamental en tareas como la clasificación de imágenes, el reconocimiento de voz y la predicción de series temporales. Su evolución ha estado marcada por el desarrollo de algoritmos como las máquinas de soporte vectorial y, más recientemente, las redes neuronales profundas, que han permitido avances significativos en precisión y capacidad de generalización.
En el ámbito del aprendizaje automático, una de las técnicas fundamentales para mejorar la capacidad de un modelo para clasificar datos es la transformación de características. A menudo, los datos en su forma original no son linealmente separables, lo que significa que no se puede trazar una línea recta (o un hiperplano en dimensiones superiores) que divida los datos en sus respectivas clases. Sin embargo, al aplicar una transformación adecuada, es posible mapear los datos a un espacio donde se vuelven linealmente separables. Un ejemplo clásico de esto es el caso de dos conjuntos de datos concéntricos en forma de anillo en un espacio de coordenadas cartesianas. En este espacio, los datos no son linealmente separables. Sin embargo, al transformar estos datos a coordenadas polares, donde cada punto se representa por su distancia al origen (r) y su ángulo (\(\theta\)), los datos se vuelven linealmente separables en el espacio transformado. A continuación, se presenta un ejemplo en Python que ilustra este concepto.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import FunctionTransformer
from sklearn.pipeline import make_pipeline
# Generar datos en forma de círculos concéntricos
X, y = make_circles(n_samples=300, noise=0.05, factor=0.5, random_state=42)
# Función para transformar a coordenadas polares
def cartesian_to_polar(X):
r = np.sqrt(X[:, 0]**2 + X[:, 1]**2)
theta = np.arctan2(X[:, 1], X[:, 0])
return np.vstack((r, theta)).T
# Crear un modelo de regresión logística con transformación de coordenadas
model = make_pipeline(FunctionTransformer(cartesian_to_polar, validate=True), LogisticRegression())
# Entrenar el modelo
model.fit(X, y)
# Visualizar los datos originales
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', edgecolor='k')
plt.title('Datos en Coordenadas Cartesianas')
plt.xlabel('X')
plt.ylabel('Y')
plt.grid(True)
# Visualizar la separación en el espacio transformado
plt.subplot(1, 2, 2)
X_polar = cartesian_to_polar(X)
plt.scatter(X_polar[:, 0], X_polar[:, 1], c=y, cmap='viridis', edgecolor='k')
plt.title('Datos en Coordenadas Polares')
plt.xlabel('r')
plt.ylabel(r'$\theta$')
plt.grid(True)
plt.tight_layout()
plt.show()
En este ejemplo, los datos originales en coordenadas cartesianas (X, Y) forman dos anillos concéntricos que no pueden ser separados por una línea recta. Sin embargo, al transformar estos datos a coordenadas polares (r, θ), la característica radial (r) permite separar los datos de manera lineal, ya que los puntos de diferentes clases tienen diferentes distancias al origen. Este tipo de transformación es una poderosa herramienta en el aprendizaje automático, ya que permite que modelos lineales simples, como la regresión logística, resuelvan problemas que inicialmente parecen requerir modelos más complejos.
Por otro lado, el aprendizaje no supervisado aborda el desafío de encontrar patrones ocultos en datos no etiquetados. Este paradigma es especialmente relevante en situaciones donde la anotación de datos es costosa o imposible. A lo largo de los años, el aprendizaje no supervisado ha evolucionado desde técnicas básicas de agrupamiento, como el algoritmo k-means, hasta métodos más complejos como los autoencoders y las redes generativas adversarias (GANs). Estos avances han permitido aplicaciones innovadoras, como la reducción de dimensionalidad y la generación de datos sintéticos, ampliando las fronteras de lo que es posible en el análisis de datos.
Finalmente, el aprendizaje por refuerzo se inspira en la forma en que los seres vivos aprenden a través de la interacción con su entorno. En este enfoque, un agente aprende a tomar decisiones secuenciales mediante un proceso de prueba y error, recibiendo recompensas o castigos en función de las acciones que realiza. Este paradigma ha ganado prominencia en los últimos años, especialmente con el desarrollo de algoritmos de aprendizaje profundo por refuerzo que han logrado hazañas impresionantes, como vencer a campeones humanos en juegos complejos como el Go y el ajedrez. La evolución del aprendizaje por refuerzo refleja un cambio hacia sistemas más autónomos y adaptativos, capaces de aprender comportamientos complejos en entornos dinámicos.
En conjunto, estos tres paradigmas del aprendizaje automático han transformado nuestra capacidad para analizar y modelar datos, abriendo nuevas oportunidades para la investigación y la innovación en física y otras disciplinas científicas. A medida que continuamos explorando sus aplicaciones, es esencial comprender las fortalezas y limitaciones de cada enfoque, así como su evolución histórica, para aprovechar al máximo su potencial en la resolución de problemas complejos.
El aprendizaje profundo ha emergido como una subdisciplina del aprendizaje automático que ha revolucionado la forma en que abordamos problemas complejos de análisis de datos y modelado. Este enfoque se basa en el uso de redes neuronales artificiales con múltiples capas, conocidas como redes neuronales profundas, que son capaces de aprender representaciones jerárquicas de los datos. A diferencia de los métodos tradicionales de aprendizaje automático, que a menudo requieren de un preprocesamiento intensivo y la extracción manual de características, el aprendizaje profundo permite que los modelos descubran automáticamente las características relevantes directamente a partir de los datos brutos. Este avance ha sido posible gracias a mejoras en algoritmos de optimización, la disponibilidad de grandes conjuntos de datos y el incremento del poder computacional, especialmente a través del uso de unidades de procesamiento gráfico (GPUs). En los últimos años, el aprendizaje profundo ha demostrado ser extraordinariamente eficaz en una amplia gama de aplicaciones, desde el reconocimiento de imágenes y el procesamiento del lenguaje natural hasta la simulación de fenómenos físicos complejos. Al integrar el aprendizaje profundo con principios físicos, se abre un nuevo horizonte de posibilidades, permitiendo a los científicos y ingenieros desarrollar modelos más precisos y eficientes que respeten las leyes fundamentales de la naturaleza.
Para entender los siguientes ejemplos, es recomendable tener un conocimiento básico de Python. En caso que no conozca las librerías que se utilizan en estas notas recomendamos primero visitar el apéndice Apéndice: Introducción a librerías de Python útiles.
1.2.1. Ejemplo de aprendizaje supervisado#
Supongamos que queremos predecir la temperatura diaria de una ciudad en función de diversas características climáticas. Disponemos de un conjunto de datos históricos que incluye la temperatura máxima del día anterior, la humedad promedio, la velocidad del viento y la cantidad de precipitación. Nuestro objetivo es construir un modelo de aprendizaje automático supervisado que pueda predecir la temperatura máxima del día siguiente.
# Importar las bibliotecas necesarias
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Generar un conjunto de datos sintético
np.random.seed(0)
n_samples = 100
X = np.random.rand(n_samples, 4) # Características: temperatura anterior, humedad, viento, precipitación
y = 30 + 10 * X[:, 0] - 5 * X[:, 1] + 2 * X[:, 2] + np.random.randn(n_samples) # Temperatura máxima
# Dividir el conjunto de datos en entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Crear y entrenar el modelo de regresión lineal
model = LinearRegression()
model.fit(X_train, y_train)
# Realizar predicciones
y_pred = model.predict(X_test)
# Evaluar el modelo
mse = mean_squared_error(y_test, y_pred)
print(f"Error cuadrático medio: {mse:.2f}")
# Mostrar los coeficientes del modelo
print("Coeficientes del modelo:", model.coef_)
Para visualizar el resultado del modelo ajustado, podemos crear un gráfico que compare las predicciones del modelo con los valores reales de la temperatura máxima en el conjunto de prueba. Un gráfico de dispersión es una buena opción para este propósito, ya que permite observar cómo se alinean las predicciones con los valores reales.
A continuación, se muestra cómo crear este gráfico utilizando Matplotlib:
import matplotlib.pyplot as plt
# Crear un gráfico de dispersión de los valores reales vs. las predicciones
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue', alpha=0.5, label='Predicciones')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2, label='Ideal')
plt.xlabel('Valores Reales')
plt.ylabel('Predicciones')
plt.title('Comparación de Predicciones del Modelo de Regresión Lineal')
plt.legend()
plt.grid(True)
plt.show()
Este ejemplo es un caso clásico de aprendizaje supervisado, un enfoque en el que un modelo se entrena utilizando un conjunto de datos etiquetados. En el aprendizaje supervisado, el objetivo principal es aprender una función que mapea entradas a salidas basándose en ejemplos de pares de entrada-salida proporcionados durante el proceso de entrenamiento. En este caso específico, el conjunto de datos sintético contiene tanto características de entrada como una variable objetivo. Las características de entrada incluyen variables como la temperatura anterior, la humedad, el viento y la precipitación, mientras que la variable objetivo es la temperatura máxima que se desea predecir.
Durante el proceso de entrenamiento, el modelo de regresión lineal utiliza estos pares de entrada-salida para aprender la relación subyacente entre las características de entrada y la variable objetivo. El modelo ajusta sus parámetros, en este caso, los coeficientes de la regresión, con el fin de minimizar la diferencia entre las predicciones del modelo y los valores reales de la variable objetivo. Una vez que el modelo ha sido entrenado, se evalúa en un conjunto de datos de prueba que también contiene entradas y salidas conocidas. El modelo genera predicciones para las entradas del conjunto de prueba, y estas predicciones se comparan con los valores reales para evaluar el rendimiento del modelo.
En resumen, este ejemplo ilustra el aprendizaje supervisado porque el modelo se entrena con datos etiquetados y aprende a predecir la salida, que es la temperatura máxima, a partir de las entradas, que son las características climáticas, basándose en ejemplos previos. Este enfoque permite al modelo generalizar a nuevos datos y realizar predicciones precisas en situaciones similares a las observadas durante el entrenamiento.
1.2.2. Ejemplo de Aprendizaje No Supervisado: Agrupamiento de Estados#
Uno de los desafíos común es es clasificar distintos estados basados en sus propiedades intrínsecas. Supongamos que tenemos un conjunto de datos que representa diferentes estados. Supongamos que no contamos con etiquetas que indiquen a qué categoría pertenece cada estado, el objetivo es identificar patrones o grupos dentro de estos datos que puedan sugerir diferencias.
Para abordar este problema, utilizaremos el algoritmo de agrupamiento k-means, una técnica de aprendizaje no supervisado que busca dividir un conjunto de datos en k grupos distintos, donde cada grupo contiene datos similares entre sí.
Generaremos un conjunto de datos sintético que simula las características de los estados utilizando la librería scikit-learn.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# Generar un conjunto de datos sintético
np.random.seed(42)
X, _ = make_blobs(n_samples=300, centers=3, cluster_std=0.60, random_state=0)
Luego, utilizando la misma librería aplicaremos el algoritmo k-means para clasificar los datos en grupos. Finalmente, visualizaremos los resultados utilizando Matplotlib para observar cómo se agrupan los estados.
# Aplicar el algoritmo k-means
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
# Visualizar los resultados
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75, marker='X', label='Centroides')
plt.title('Agrupamiento de Estados')
plt.xlabel('Característica 1')
plt.ylabel('Característica 2')
plt.legend()
plt.grid(True)
plt.show()
En este gráfico, cada punto representa un estado cuántico, y los colores indican el grupo al que pertenece cada estado según el algoritmo k-means. Los centroides de los grupos están marcados con una ‘X’ roja, indicando el centro de cada grupo identificado. Este ejemplo es un caso de aprendizaje no supervisado porque no se utilizan etiquetas predefinidas para guiar el proceso de agrupamiento. En lugar de ello, el algoritmo identifica patrones y similitudes inherentes en los datos para agruparlos en categorías significativas. Este enfoque es particularmente útil en situaciones donde las etiquetas no están disponibles o son difíciles de definir, permitiendo a los investigadores descubrir estructuras ocultas en los datos que podrían no ser evidentes a simple vista. Ojo, en este ejemplo se fijó el numero de clústers del algoritmo KMeans de antemano en 3. Este es un hiper-parámetro del algoritmo, pero suponemos que teníamos alguna información acerca del número de estados posibles.
1.2.3. Ejemplo de Aprendizaje por Refuerzo: Control de un Péndulo Simple#
VER: https://docs.pytorch.org/tutorials/intermediate/reinforcement_q_learning.html
En este ejemplo, consideramos el problema de controlar un péndulo simple para que se mantenga en posición vertical. El péndulo puede ser empujado hacia la izquierda o hacia la derecha con una fuerza limitada, y el objetivo es aprender una política que mantenga el péndulo lo más cerca posible de la posición vertical. Este problema es un clásico en el aprendizaje por refuerzo y es más sencillo de entender para estudiantes de grado, ya que ilustra cómo un agente puede aprender a controlar un sistema físico mediante la interacción continua con el entorno.
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
import matplotlib.pyplot as plt
# Inicializar el almacentamiento de la recompensa
recompesa_epoch = []
# definición de la política
class PolicyNetwork(nn.Module):
def __init__(self):
super(PolicyNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 128),
nn.ReLU(),
nn.Linear(128, 2),
nn.Softmax(dim=-1),
)
def forward(self, x):
return self.fc(x)
# calcular la pérdida de recompensa
def compute_discounted_rewards(rewards, gamma=0.99):
discounted_rewards = []
R = 0
for r in reversed(rewards):
R = r + gamma * R
discounted_rewards.insert(0, R)
discounted_rewards = torch.tensor(discounted_rewards)
discounted_rewards = (discounted_rewards - discounted_rewards.mean()) / (discounted_rewards.std() + 1e-5)
return discounted_rewards
# Loop de entrenamiento
def train(env, policy, optimizer, episodes=1000):
for episode in range(episodes):
state = env.reset()
log_probs = []
rewards = []
done = False
while not done:
state = torch.FloatTensor(state).unsqueeze(0)
probs = policy(state)
m = Categorical(probs)
action = m.sample()
state, reward, done, _ = env.step(action.item())
log_probs.append(m.log_prob(action))
rewards.append(reward)
# Inside the train function, after an episode ends:
if done:
episode_rewards.append(sum(rewards))
discounted_rewards = compute_discounted_rewards(rewards)
policy_loss = []
for log_prob, Gt in zip(log_probs, discounted_rewards):
policy_loss.append(-log_prob * Gt)
optimizer.zero_grad()
policy_loss = torch.cat(policy_loss).sum()
policy_loss.backward()
optimizer.step()
if episode % 50 == 0:
print(f"Episode {episode}, Total Reward: {sum(rewards)}")
break
env = gym.make('CartPole-v1')
policy = PolicyNetwork()
optimizer = optim.Adam(policy.parameters(), lr=1e-2)
train(env, policy, optimizer)
plt.plot(episode_rewards)
plt.title('Training Reward Over Episodes')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.show()
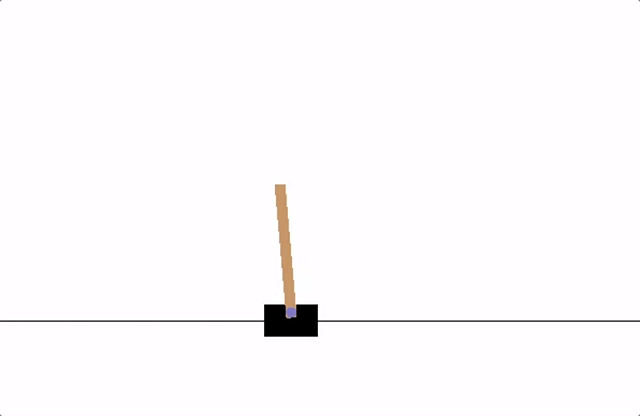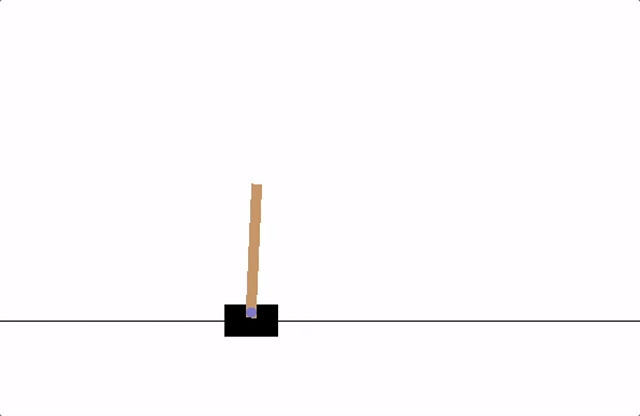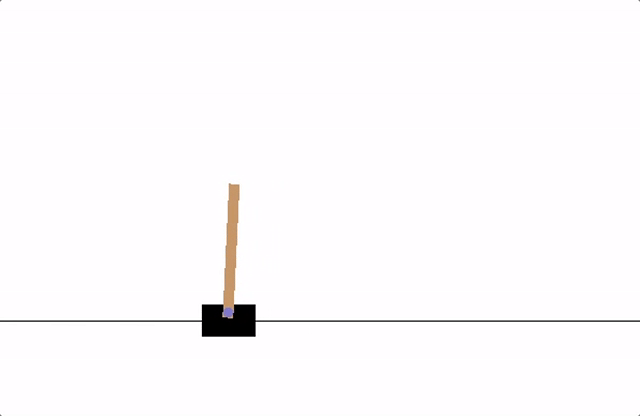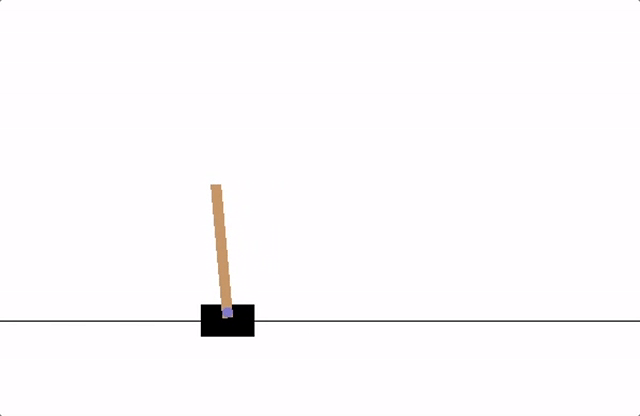
En este ejemplo, hemos implementado un agente de aprendizaje por refuerzo que aprende a controlar un péndulo simple para mantenerlo en posición vertical. El entorno simula el comportamiento físico del péndulo, donde el agente puede aplicar un torque limitado para influir en su movimiento. La recompensa está diseñada para penalizar grandes desviaciones del ángulo vertical, así como velocidades angulares altas y el uso excesivo de torque. A través de la interacción continua con el entorno, el agente ajusta sus acciones para maximizar la recompensa total, aprendiendo así a mantener el péndulo en equilibrio. Este ejemplo ilustra de manera sencilla cómo el aprendizaje por refuerzo puede aplicarse a problemas de control en física, permitiendo que un agente descubra estrategias óptimas mediante la experimentación y la retroalimentación.
1.2.4. Funciones de costo#
La función de costo cuantifica el grado de discrepancia en las predicciones del modelo propuesto y la información disponible (ya sea en forma de datos observados, etiquetas conocidas, etc.).
Una función de costo \(\mathcal{L}(w)\) es una función escalar que depende de los parámetros del modelo \(w\). El entrenamiento de un modelo de aprendizaje automático consiste en resolver un problema de optimización, típicamente no lineal y de dimensionalidad alta, en la que se busca minimizar dicha función. Es decir, se busca \(w^{*}\) tal que
La elección de la función de costo resulta un elemento central del diseño de cualquier algoritmo de aprendizaje, ya que define qué significa “aprender” en el contexto del problema considerado.
Más allá de medir errores respecto a datos, las funciones de costo pueden incorporar conocimiento previo sobre el sistema que se desea modelar. Esto se logra añadiendo términos que penalizan comportamientos no deseados o que refuerzan propiedades estructurales específicas, como simetrías, conservación de magnitudes o cumplimiento de restricciones o constraints físicos. Desde esta prespectiva es que la función de costo deja de ser un mero instrumento técnico y permite codificar hipótesis sobre la realidad subyacente. En los modelos actuales de aprendizaje profundo, esta flexibilidad resulta clave para abordar problemas complejos con datos escasos o ruidosos.
En lo que sigue introduciré a algunas funciones de costo clásicas que luego utilizaremos a lo largo del curso. Sin embargo, este resúmen no intenta ser completo sino proveer de ideas para que luego puedan desarrollar sus propias funciones de costo. Grandes saltos en innovación en modelos de aprendizaje automático se han dado a partir de plantear nuevas funciones de costo apropiadas al problema de interés.
Clasificación#
En los problemas de clasificación, el objetivo del modelo es asignar una observación de entrada (\(x\)) a una o varias clases discretas. Las funciones de costo cuantifican la discrepancia entre la predicción del modelo y la etiqueta verdadera, y están estrechamente relacionadas con interpretaciones probabilísticas y criterios de decisión óptimos.
La pérdida 0–1 es la función de costo conceptualmente más simple. Penaliza cualquier clasificación incorrecta con un valor unitario, sin tener en cuenta el grado de confianza del modelo.
Aunque es una métrica natural para evaluar clasificadores, no es diferenciable y, por tanto, no resulta adecuada para el entrenamiento mediante métodos basados en gradiente.
La entropía cruzada binaria (también conocida como log-loss, o pérdida logística) resulta útil cuando el modelo produce una probabilidad (\(p = P(y=1 \mid x)\)), y se define como
donde \(y \in \{0,1\}\). Esta función se deriva del principio de máxima verosimilitud asumiendo un modelo Bernoulli y es convexa respecto a \(p\). Penaliza fuertemente las predicciones confiadas (\(p\) grande) pero incorrectas.
En clasificación multiclase con \(K\) clases mutuamente excluyentes, se emplea típicamente la función softmax para obtener probabilidades
donde \(z_k\) son los logits (\(\frac{p}{1-p}\)) del modelo. La entropía cruzada categórica se define como
donde \(y_k\) es una codificación one-hot de la clase verdadera. Esta pérdida mide la divergencia entre la distribución verdadera y la predicha, y es el estándar en redes neuronales para clasificación multiclase.
En problemas de clasificación multietiqueta, donde cada instancia puede pertenecer simultáneamente a varias clases, se aplica la entropía cruzada binaria de manera independiente a cada etiqueta:
donde \(y_k \in \{0,1\}\) indica la presencia o ausencia de la etiqueta \(k\).
Regresión#
En los problemas de regresión, el objetivo del modelo es aproximar una variable continua \(y \in \mathbb{R}\) a partir de una entrada \(x\). Las funciones de costo cuantifican el error entre la predicción \(\hat{y} = f(x)\) del modelo y el valor real observado, y su elección determina las propiedades estadísticas y numéricas del estimador aprendido.
El error cuadrático medio es la función de costo más común en regresión. Se define como
Esta función penaliza de forma cuadrática los errores grandes y es diferenciable en todo su dominio. Desde un punto de vista estadístico, equivale a maximizar la verosimilitud bajo el supuesto de ruido gaussiano con varianza constante.
El error absoluto medio mide la desviación promedio en valor absoluto entre la predicción y el valor real:
Esta función es más robusta frente a valores atípicos que el MSE, aunque no es diferenciable en \(y_i = \hat{y}_i\), lo que puede dificultar su optimización en algunos contextos.
En situaciones donde las observaciones tienen distinta confiabilidad, se utiliza una versión ponderada del MSE:
donde \(w_i > 0\) representa el peso asociado a la observación \(i\). Este enfoque es habitual cuando se dispone de estimaciones de la varianza del ruido.
La pérdida de Huber combina las ventajas del MSE y del MAE, siendo cuadrática para errores pequeños y lineal para errores grandes:
donde \(\delta\) es un parámetro que controla el punto de transición. Esta pérdida es ampliamente utilizada por su robustez y buenas propiedades de optimización.
Otro ejemplo interesante de función de costo es la pérdida log-cosh se define como
Para errores pequeños se comporta de manera similar al MSE, mientras que para errores grandes crece aproximadamente de forma lineal, lo que la hace robusta frente a outliers y completamente diferenciable.
Una familia general de funciones de costo en regresión está dada por la norma \(L_p\):
donde \(p \ge 1\). Los casos \(p=1\) y \(p=2\) corresponden al MAE y al MSE, respectivamente. El valor de \(p\) controla el compromiso entre robustez y sensibilidad a errores grandes.
1.2.5. Optimizadores#
Para entrenar un modelo de aprendizaje automático, es decesario proveer o alimentar de datos al modelo y observar la salida, comparar la salida con lo esperado mediante la función de costo y decidir con cierto criterio cómo modificar los parámetros del modelo para que en la siguiente iteración de alimentar los datos y evaluar se obtenga un valor de función de costo menor. Este proceso se repite iterativamente hasta que la función de costo ya no se puede minimizar más o no se observan cambios sustanciales de la función de costo luego de una determinada cantidad de iteraciones. El algoritmo que decide cómo modificar los parámetros del modelo se le llama optimizador y es el responsable del aprendizaje del modelo.
Cabe mencionar que no es necesario pasar todos los datos al modelo para calcular el valor de la función de costo. Esto es posible, pero costoso computacionalmente y lento ya que un paso de optimización de parámetros se dará por vuelta entera de los datos por el modelo (si la cantidad de datos es importante, esto se vuelve lento) y a su vez, la decisión de hacia dónde optimizar estará promediada sobre toda la variabilidad en el conjunto de datos, lo que hará tomar una decisión suavizada, que probablemente converga lentamente (o no permita salir de mínimos locales). Es por esto que se estila entrenar en mini-batches, conjuntos de 32, 64, 128, 256 o más datos por evaluación de la función de costo y toma de decisión del optimizador. De este modo, la optimización se va llevando a cabo más frecuentemente, de manera un poco más aleatoria, pero permitiendo la exploración del espacio de parámetros más exhaustiva. Una vez que el modelo vio todos los datos, se vuelve a repetir el proceso. Cada vez que todos los datos pasan por el modelo (varias instancias de optimización de los parámetros mediante el concepto de mini-batches) se llama una época y los modelos suelen entrenarse por varias épocas.
Respecto al problema de optimización planteado en la sección de función de costo, el gran número de parámetros, la no convexidad de la función objetivo y el uso de grandes volúmenes de datos hacen que los métodos clásicos de optimización determinista resultan impracticables. En este contexto, los optimizadores basados en gradiente estocástico constituyen el estándar para la optimización de funciones de costo en problemas de aprendizaje automático profundo.
A continuación describiré algunos de los optimizadores más utilizados al momento, aclarando que existen distintas versiones y algunos algoritmos que no presento aquí. Para una descripción más detallada, ver [3].
Descenso por gradiente estocástico (SGD)#
El descenso por gradiente estocástico es la base conceptual de la mayoría de los optimizadores modernos. En su forma más simple, actualiza los parámetros en la dirección opuesta al gradiente de la función de costo, estimado sobre un mini-batch de datos:
donde \(\eta > 0\) es la tasa de aprendizaje y \(\nabla_w \mathcal{L}_t\) representa el gradiente calculado en el paso \(t\).
SGD es simple, eficiente en memoria y presenta buenas propiedades de generalización. Sin embargo, puede converger lentamente y ser sensible a la elección de la tasa de aprendizaje, especialmente en funciones de costo mal condicionadas.
SGD con momento (Momentum)#
El método de momento introduce una variable auxiliar \(v_t\) que acumula una media exponencial de los gradientes pasados, reduciendo oscilaciones y acelerando la convergencia en direcciones consistentes:
donde \(\mu \in [0,1)\) es el coeficiente de momento.
Este enfoque puede interpretarse como una analogía física, en la que los parámetros se mueven con inercia sobre el paisaje de la función de costo, lo que resulta especialmente eficaz en valles alargados y superficies anisotrópicas.
RMSProp#
RMSProp es un optimizador adaptativo que ajusta de forma automática la tasa de aprendizaje de cada parámetro en función de la magnitud reciente de sus gradientes. Mantiene una media móvil del cuadrado del gradiente:
y actualiza los parámetros según
donde \(\rho \in [0,1)\) es el factor de decaimiento y \(\epsilon\) es un término pequeño para garantizar estabilidad numérica.
RMSProp es especialmente útil en problemas no estacionarios y cuando las escalas de los gradientes difieren significativamente entre parámetros.
Adam (Adaptive Moment Estimation)#
Adam combina las ideas de momento y escalado adaptativo del gradiente. Mantiene estimaciones de primer y segundo orden del gradiente:
junto con correcciones por sesgo debidas a la inicialización:
La actualización final de los parámetros es
Adam ofrece una convergencia rápida y estable en una amplia gama de problemas, lo que explica su uso generalizado como optimizador por defecto en aprendizaje profundo. No obstante, en algunos casos puede mostrar peores propiedades de generalización que SGD con momento.
La elección del optimizador tiene un impacto directo en la velocidad de convergencia, la estabilidad numérica y la capacidad de generalización del modelo. Mientras que Adam y RMSProp son preferidos por su robustez y facilidad de uso, SGD con momento sigue siendo una opción de referencia cuando se prioriza el control fino del proceso de entrenamiento y el desempeño en generalización. En contextos como el aprendizaje profundo basado en la física, la interacción entre la función de costo y el optimizador adquiere un papel central, ya que términos físicos pueden introducir escalas y rigideces adicionales en el problema de optimización.
1.3. De la regresión lineal a las redes neuronales#
La transición de la regresión lineal a las redes neuronales representa un avance significativo en la capacidad de los modelos para capturar y aprender patrones complejos en los datos. La regresión lineal es uno de los métodos más básicos y ampliamente utilizados en el aprendizaje automático. Se basa en la idea de encontrar una relación lineal entre las variables de entrada y la variable de salida, ajustando un hiperplano en un espacio de características que minimiza el error cuadrático medio entre las predicciones y los valores reales. Aunque es eficaz para problemas donde la relación entre las variables es aproximadamente lineal, su capacidad para modelar interacciones no lineales es limitada. Esto restringe su aplicabilidad en escenarios donde los datos presentan relaciones más complejas.
Las redes neuronales, por otro lado, son modelos inspirados en el funcionamiento del cerebro humano, capaces de aprender representaciones jerárquicas de los datos. A diferencia de la regresión lineal, las redes neuronales consisten en múltiples capas de nodos (o neuronas), donde cada capa puede aprender diferentes niveles de abstracción. Las capas ocultas permiten a las redes neuronales capturar interacciones no lineales entre las variables de entrada, lo que las hace extremadamente poderosas para una amplia gama de aplicaciones, desde el reconocimiento de imágenes hasta el procesamiento del lenguaje natural. La capacidad de las redes neuronales para aproximar funciones complejas las convierte en una herramienta esencial en el aprendizaje profundo, donde se busca modelar fenómenos intrincados y extraer patrones significativos de grandes volúmenes de datos. Esta evolución desde la regresión lineal hacia las redes neuronales ha sido fundamental para el desarrollo de técnicas avanzadas de inteligencia artificial que hoy en día están transformando múltiples industrias.
El perceptrón multicapa, también conocido como MLP (por sus siglas en inglés, Multi-Layer Perceptron), es una extensión del perceptrón simple que permite a las redes neuronales aprender y representar funciones más complejas. Mientras que un perceptrón simple consiste en una sola capa de nodos de entrada conectados directamente a una salida, el perceptrón multicapa introduce una o más capas ocultas entre la capa de entrada y la capa de salida. Estas capas ocultas permiten al MLP capturar relaciones no lineales en los datos, lo que lo hace mucho más poderoso y versátil.
Matemáticamente, un MLP se compone de múltiples capas de neuronas, donde cada neurona en una capa está conectada a todas las neuronas de la capa siguiente. Cada conexión tiene un peso asociado, y cada neurona tiene un sesgo. La salida de una neurona se calcula como una función de activación aplicada a la suma ponderada de sus entradas más el sesgo. Para una neurona \(j\) en una capa oculta, la salida \(h_j\) se puede expresar como:
donde \(x_i\) son las entradas a la neurona, \(w_{ij}\) son los pesos de las conexiones, \(b_j\) es el sesgo, y \(f\) es la función de activación, que introduce no linealidad en el modelo. Comúnmente, se utilizan funciones de activación como la sigmoide, la tangente hiperbólica o la ReLU (Rectified Linear Unit).
La capa de salida del MLP produce la predicción final del modelo. Si el MLP se utiliza para clasificación, la capa de salida suele aplicar una función de activación como softmax para convertir las salidas en probabilidades. El entrenamiento de un MLP implica ajustar los pesos y sesgos para minimizar una función de pérdida, que mide la discrepancia entre las predicciones del modelo y los valores reales. Este ajuste se realiza mediante un proceso iterativo conocido como retropropagación, que utiliza el descenso de gradiente para actualizar los pesos en función de los gradientes de la función de pérdida con respecto a los pesos.
El perceptrón multicapa es un componente fundamental en el aprendizaje profundo, ya que forma la base de arquitecturas más complejas como las redes neuronales convolucionales y las redes neuronales recurrentes. Su capacidad para aprender representaciones jerárquicas de los datos lo convierte en una herramienta poderosa para abordar problemas de aprendizaje automático que involucran patrones complejos y no lineales.
Para ilustrar el concepto de un perceptrón multicapa (MLP) utilizando PyTorch, consideremos un ejemplo sencillo de clasificación de datos generados sintéticamente. Supongamos que queremos clasificar puntos en un plano en dos categorías distintas. Utilizaremos un MLP con una capa oculta para aprender esta tarea de clasificación.
Primero, generamos un conjunto de datos sintético utilizando make_moons de Scikit-learn, que crea dos grupos de datos en forma de media luna. Estos datos no son linealmente separables, lo que hace que un MLP sea una opción adecuada para la clasificación.
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Generar datos sintéticos
X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
X_train_orig, X_test_orig, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Escalar los datos
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train_orig)
X_test = scaler.transform(X_test_orig)
# Convertir los datos a tensores de PyTorch
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
# Definir el modelo de perceptrón multicapa
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.hidden = nn.Linear(2, 10) # Capa oculta con 10 neuronas
self.output = nn.Linear(10, 2) # Capa de salida con 2 neuronas (para 2 clases)
def forward(self, x):
x = torch.relu(self.hidden(x))
x = self.output(x)
return x
# Crear el modelo, definir la función de pérdida y el optimizador
model = MLP()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# Entrenar el modelo
num_epochs = 300
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# Evaluar el modelo
with torch.no_grad():
outputs = model(X_test_tensor)
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == y_test_tensor).sum().item() / y_test_tensor.size(0)
print(f'Accuracy: {accuracy:.4f}')
# Crear una malla de puntos para visualizar la frontera de decisión
h = 0.02 # Paso en la malla
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
grid = np.c_[xx.ravel(), yy.ravel()]
grid_scaled = scaler.transform(grid)
grid_tensor = torch.tensor(grid_scaled, dtype=torch.float32)
# Predecir las clases para cada punto en la malla
with torch.no_grad():
Z = model(grid_tensor)
_, Z = torch.max(Z, 1)
Z = Z.numpy().reshape(xx.shape)
# Visualizar los resultados
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.3, cmap='viridis')
plt.scatter(X_test_orig[:, 0], X_test_orig[:, 1], c=y_test, cmap='viridis', marker='o', edgecolor='k', s=50)
plt.scatter(X_train_orig[:, 0], X_train_orig[:, 1], c=y_train, cmap='viridis', marker='x', s=30, alpha=0.6)
plt.title('Clasificación del Perceptrón Multicapa')
plt.xlabel('Característica 1')
plt.ylabel('Característica 2')
plt.show()
En este ejemplo, hemos definido un MLP con una capa oculta que contiene 10 neuronas y una capa de salida con 2 neuronas, correspondiente a las dos clases de nuestro problema de clasificación. La función de activación ReLU se utiliza en la capa oculta para introducir no linealidad en el modelo. Durante el entrenamiento, el modelo ajusta sus pesos para minimizar la función de pérdida de entropía cruzada, que mide la discrepancia entre las predicciones del modelo y las etiquetas reales. Utilizamos el optimizador Adam para actualizar los pesos de manera eficiente.
Después del entrenamiento, evaluamos el modelo en un conjunto de prueba y calculamos la precisión de las predicciones. Finalmente, visualizamos los resultados de la clasificación en un gráfico de dispersión, donde los puntos están coloreados según la clase predicha por el modelo. Este ejemplo demuestra cómo un perceptrón multicapa puede aprender a clasificar datos no linealmente separables, aprovechando su capacidad para capturar patrones complejos en los datos.
Ian Goodfellow. Deep learning. 2016.
Douglas B Lenat and Ramanathan V Guha. Building large knowledge-based systems; representation and inference in the Cyc project. Addison-Wesley Longman Publishing Co., Inc., 1989.
Christopher M Bishop and Hugh Bishop. Deep learning: Foundations and concepts. Springer Nature, 2023.