Autoencoder y Variational Autoencoder (VAE) en MNIST#
![]()
En esta notebook construimos primero un autoencoder (AE) y luego dos variantes de Variational Autoencoder (VAE) usando PyTorch sobre MNIST.
Idea general#
Un autoencoder aprende dos mapas:
Encoder: lleva una imagen
xa una representación latentez.Decoder: intenta reconstruir la imagen original a partir de
z.
La diferencia central entre ambos modelos es:
En un AE, el espacio latente es determinista.
En un VAE, el encoder produce una distribución sobre el espacio latente y el modelo se entrena para que ese espacio sea estructurado y muestreable.
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch import nn
from torch.utils.data import DataLoader, Subset
from torchvision import datasets, transforms
SEED = 42
np.random.seed(SEED)
torch.manual_seed(SEED)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
DEVICE
device(type='cpu')
Carga de datos#
MNIST contiene imágenes de dígitos manuscritos de tamaño 28 x 28. Las normalizamos al intervalo [0, 1].
Para que la notebook siga siendo relativamente rápida, usamos un subconjunto moderado del dataset.
transform = transforms.ToTensor()
trainset = datasets.MNIST(
root='./data', # A donde se guardan los datos
train=True, # Si queremos la partición de entrenamiento o evaluación
download=True, # descarga de datos si no ya presente
transform=transform # transformaciones a los datos
)
test_dataset = datasets.MNIST(
root="./data",
train=False,
download=True,
transform=transform)
train_subset = Subset(trainset, range(20000))
test_subset = Subset(test_dataset, range(4000))
batch_size = 128
train_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_subset, batch_size=batch_size, shuffle=False)
print(f"Train batches: {len(train_loader)}")
print(f"Test batches: {len(test_loader)}")
Train batches: 157
Test batches: 32
Veamos algunas imágenes y sus etiquetas
images, labels = next(iter(train_loader))
fig, axes = plt.subplots(2, 6, figsize=(9, 3))
for ax, img, label in zip(axes.flat, images[:12], labels[:12]):
ax.imshow(img.squeeze(0), cmap="gray")
ax.set_title(f"label={label.item()}")
ax.axis("off")
plt.tight_layout()
plt.show()

Autoencoder clásico#
Un AE busca aprender una representación comprimida \(z = h_\phi(x)\) y una reconstrucción \(\hat{x} = f_\theta(z)\) minimizando un error de reconstrucción.
En forma simple:
y se entrena con una pérdida del tipo
El Autoencoder aprende una compresión útil para reconstruir los datos, es decir, una representación latente que suele ser de menor dimensionalidad, en donde se intentan separa patrones relevantes. Aunque el AE reconstruya bien, no obliga a que los puntos del espacio latente sigan una distribución simple. Por eso, si tomamos un z aleatorio, el decoder puede producir una resultado sin el sentido esperado. Esa es una de las razones para pasar a un VAE.
En esta notebook usamos una reconstrucción basada en binary cross-entropy porque los píxeles de MNIST están en [0,1] y el decoder puede interpretarse como una probabilidad por píxel.
class Autoencoder(nn.Module):
def __init__(self, latent_dim=2):
super().__init__()
self.encoder = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, latent_dim),
)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 28 * 28),
)
def forward(self, x):
z = self.encoder(x)
logits = self.decoder(z)
return logits.view(-1, 1, 28, 28), z
def ae_loss(x_logits, x):
return nn.functional.binary_cross_entropy_with_logits(x_logits, x, reduction="sum") / x.size(0)
@torch.no_grad()
def show_reconstructions(model, loader, n=8, title="Reconstrucciones"):
model.eval()
x, _ = next(iter(loader))
x = x.to(DEVICE)
logits, _ = model(x)
x_hat = torch.sigmoid(logits)
# x_hat = (x_hat > 0.5).float()
# x = (x.cpu() > 0.5).float()
fig, axes = plt.subplots(2, n, figsize=(1.6 * n, 3.2))
for i in range(n):
axes[0, i].imshow(x[i, 0].cpu(), cmap="gray")
axes[0, i].axis("off")
axes[1, i].imshow(x_hat[i, 0].cpu(), cmap="gray")
axes[1, i].axis("off")
axes[0, 0].set_ylabel("original", fontsize=11)
axes[1, 0].set_ylabel("recon", fontsize=11)
fig.suptitle(title)
plt.tight_layout()
plt.show()
def train_epoch_ae(model, loader, optimizer):
model.train()
total_loss = 0.0
for x, _ in loader:
x = x.to(DEVICE)
logits, _ = model(x)
loss = ae_loss(logits, x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * x.size(0)
return total_loss / len(loader.dataset)
ae = Autoencoder(latent_dim=2).to(DEVICE)
ae_optimizer = torch.optim.Adam(ae.parameters(), lr=1e-3)
ae_history = []
ae_epochs = 100
ae_test_history = []
for epoch in range(1, ae_epochs + 1):
loss = train_epoch_ae(ae, train_loader, ae_optimizer)
ae_history.append(loss)
with torch.no_grad():
ae.eval()
loss_test = 0.0
for x, _ in test_loader:
x = x.to(DEVICE)
logits, _ = ae(x)
loss = ae_loss(logits, x)
loss_test += loss.item() * x.size(0)
loss_test /= len(test_loader.dataset)
ae_test_history.append(loss_test)
if epoch%10 == 0:
print(f"AE | epoch {epoch:02d} | loss = {loss:.4f} | test_loss = {loss_test:.4f}")
AE | epoch 10 | loss = 130.9634 | test_loss = 146.5974
AE | epoch 20 | loss = 127.3412 | test_loss = 142.4212
AE | epoch 30 | loss = 125.5546 | test_loss = 140.6660
AE | epoch 40 | loss = 124.3302 | test_loss = 139.5688
AE | epoch 50 | loss = 123.1937 | test_loss = 138.2811
AE | epoch 60 | loss = 123.5801 | test_loss = 138.2701
AE | epoch 70 | loss = 124.0624 | test_loss = 137.9626
AE | epoch 80 | loss = 129.4604 | test_loss = 138.2132
AE | epoch 90 | loss = 123.6594 | test_loss = 138.0142
AE | epoch 100 | loss = 126.7145 | test_loss = 138.6860
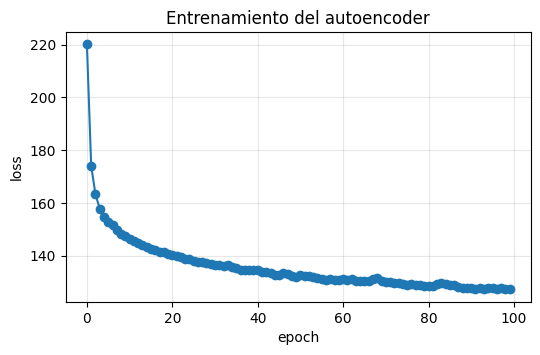
plt.figure(figsize=(6, 3.5))
plt.plot(ae_history, marker="o")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.title("Entrenamiento del autoencoder")
plt.grid(alpha=0.3)
plt.show()
show_reconstructions(ae, test_loader, title="AE: originales vs reconstrucciones")

Interpolacion en el espacio latente#
@torch.no_grad()
def interpolate_ae(model, x_start, x_end, steps=10):
model.eval()
x_start = x_start.unsqueeze(0).to(DEVICE)
x_end = x_end.unsqueeze(0).to(DEVICE)
z_start = model.encoder(x_start)
z_end = model.encoder(x_end)
alphas = torch.linspace(0.0, 1.0, steps, device=DEVICE).view(-1, 1)
z_interp = z_start * (1 - alphas) + z_end * alphas
logits = model.decoder(z_interp)
return torch.sigmoid(logits).cpu()
x_batch, y_batch = next(iter(test_loader))
idx_start, idx_end = 0, 10
x_start = x_batch[idx_start]
x_end = x_batch[idx_end]
interp_images = interpolate_ae(ae, x_start, x_end, steps=10)
fig, axes = plt.subplots(1, interp_images.size(0) + 2, figsize=(14, 2.5))
axes[0].imshow(torch.sigmoid(ae(x_start)[0]).view(28,28).detach().numpy(), cmap="gray")
axes[0].set_title(f"start: {y_batch[idx_start].item()}")
axes[0].axis("off")
for i, img in enumerate(interp_images):
axes[i + 1].imshow(img.view(28, 28), cmap="gray")
axes[i + 1].axis("off")
axes[-1].imshow(torch.sigmoid(ae(x_end)[0]).view(28,28).detach().numpy(), cmap="gray")
axes[-1].set_title(f"end: {y_batch[idx_end].item()}")
axes[-1].axis("off")
fig.suptitle("Interpolación en el espacio latente del Autoencoder")
plt.tight_layout()
plt.show()

Del AE al VAE#
El problema del AE es que el espacio latente no está regularizado. Un VAE corrige esto haciendo que el encoder ya no produzca un único vector, sino los parámetros de una distribución gaussiana:
Entonces, para cada imagen \(x\), el encoder produce:
una media \(\mu(x)\)
una varianza (o \(\log \sigma^2(x)\) para mayor estabilidad numérica)
Luego se toma una muestra latente con el truco de reparametrización:
Esto permite que el muestreo siga siendo diferenciable respecto de los parámetros del encoder.
Función de costo del VAE#
El VAE se entrena maximizando una cota inferior de la verosimilitud, conocida como ELBO. En práctica, esto equivale a minimizar:
En esta notebook elegimos:
porque:
las imágenes están normalizadas entre
0y1;el decoder produce logits por píxel;
aplicar
sigmoida esos logits da probabilidades por píxel;la BCE corresponde a un modelo Bernoulli independiente por píxel, una elección estándar para MNIST.
El término KL, cuando \(q_\phi(z|x)\) es gaussiana diagonal y \(p(z)=\mathcal{N}(0,I)\), tiene forma cerrada:
class MLPVAE(nn.Module):
def __init__(self, latent_dim=2):
super().__init__()
self.latent_dim = latent_dim
self.feature_extractor = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
)
self.mu_head = nn.Linear(128, latent_dim)
self.logvar_head = nn.Linear(128, latent_dim)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 28 * 28),
)
def encode(self, x):
h = self.feature_extractor(x)
mu = self.mu_head(h)
logvar = self.logvar_head(h).clamp(-6.0, 2.0)
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
logits = self.decoder(z)
return logits.view(-1, 1, 28, 28)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
logits = self.decode(z)
return logits, mu, logvar
class CNNVAE(nn.Module):
def __init__(self, latent_dim=2):
super().__init__()
self.latent_dim = latent_dim
self.encoder = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.SiLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.SiLU(),
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.SiLU(),
nn.Flatten(),
nn.Linear(128 * 4 * 4, 256),
nn.SiLU(),
)
self.mu_head = nn.Linear(256, latent_dim)
self.logvar_head = nn.Linear(256, latent_dim)
self.decoder_input = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.SiLU(),
nn.Linear(256, 128 * 4 * 4),
nn.SiLU(),
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.SiLU(),
nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.SiLU(),
nn.ConvTranspose2d(32, 1, kernel_size=4, stride=2, padding=1),
)
def encode(self, x):
h = self.encoder(x)
mu = self.mu_head(h)
logvar = self.logvar_head(h).clamp(-6.0, 2.0)
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = self.decoder_input(z)
h = h.view(-1, 128, 4, 4)
return self.decoder(h)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
logits = self.decode(z)
return logits, mu, logvar
def vae_loss(x_logits, x, mu, logvar, beta=1.0):
recon = nn.functional.binary_cross_entropy_with_logits(
x_logits, x, reduction="sum"
) / x.size(0)
kl = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) / x.size(0)
total = recon + beta * kl
return total, recon, kl
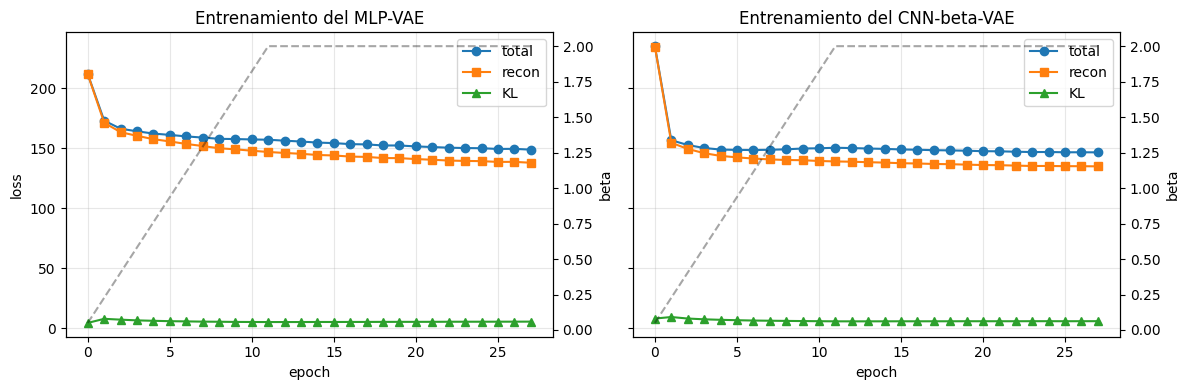
Modificación de pesos en la función de costo durante el aprendizaje#
Si el KL pesa demasiado desde el principio, el modelo puede colapsar a un latente poco informativo y reconstruir mal.
Si el KL pesa demasiado chico, el modelo reconstruye bien pero el espacio latente queda desordenado.
El KL warmup arranca con \beta pequeño y lo incrementa gradualmente. En la práctica, esto suele producir:
mejores reconstrucciones en las primeras épocas;
un espacio latente más suave y mejor separado al final.
def kl_weight_schedule(epoch, total_epochs, beta_max=2.0, warmup_epochs=12):
if epoch <= 1:
return 0.05
if epoch >= warmup_epochs:
return beta_max
progress = (epoch - 1) / max(1, warmup_epochs - 1)
return 0.05 + progress * (beta_max - 0.05)
def train_epoch_vae(model, loader, optimizer, beta):
model.train()
total_loss = 0.0
total_recon = 0.0
total_kl = 0.0
for x, _ in loader:
x = x.to(DEVICE)
logits, mu, logvar = model(x)
loss, recon, kl = vae_loss(logits, x, mu, logvar, beta=beta)
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=5.0)
optimizer.step()
total_loss += loss.item() * x.size(0)
total_recon += recon.item() * x.size(0)
total_kl += kl.item() * x.size(0)
n = len(loader.dataset)
return total_loss / n, total_recon / n, total_kl / n
latent_dim = 2
mlp_vae = MLPVAE(latent_dim=latent_dim).to(DEVICE)
cnn_vae = CNNVAE(latent_dim=latent_dim).to(DEVICE)
models = {
"MLP-VAE": {
"model": mlp_vae,
"optimizer": torch.optim.Adam(mlp_vae.parameters(), lr=1e-3),
},
"CNN-beta-VAE": {
"model": cnn_vae,
"optimizer": torch.optim.Adam(cnn_vae.parameters(), lr=8e-4),
},
}
histories = {
name: {"total": [], "recon": [], "kl": [], "beta": []}
for name in models
}
vae_epochs = 28
for epoch in range(1, vae_epochs + 1):
beta = kl_weight_schedule(epoch, vae_epochs, beta_max=2.0, warmup_epochs=12)
for name, bundle in models.items():
loss, recon, kl = train_epoch_vae(
bundle["model"],
train_loader,
bundle["optimizer"],
beta=beta,
)
histories[name]["total"].append(loss)
histories[name]["recon"].append(recon)
histories[name]["kl"].append(kl)
histories[name]["beta"].append(beta)
print(
f"{name} | epoch {epoch:02d} | beta = {beta:.2f} | "
f"total = {loss:.4f} | recon = {recon:.4f} | kl = {kl:.4f}"
)
print()
MLP-VAE | epoch 01 | beta = 0.05 | total = 211.9469 | recon = 211.7264 | kl = 4.4105
CNN-beta-VAE | epoch 01 | beta = 0.05 | total = 235.2712 | recon = 234.8699 | kl = 8.0253
MLP-VAE | epoch 02 | beta = 0.23 | total = 173.1433 | recon = 171.3707 | kl = 7.7994
CNN-beta-VAE | epoch 02 | beta = 0.23 | total = 156.7914 | recon = 154.6772 | kl = 9.3027
MLP-VAE | epoch 03 | beta = 0.40 | total = 166.3789 | recon = 163.5036 | kl = 7.1074
CNN-beta-VAE | epoch 03 | beta = 0.40 | total = 152.8178 | recon = 149.5623 | kl = 8.0475
MLP-VAE | epoch 04 | beta = 0.58 | total = 164.2604 | recon = 160.4777 | kl = 6.5015
CNN-beta-VAE | epoch 04 | beta = 0.58 | total = 150.3173 | recon = 146.0153 | kl = 7.3941
MLP-VAE | epoch 05 | beta = 0.76 | total = 162.3558 | recon = 157.6852 | kl = 6.1528
CNN-beta-VAE | epoch 05 | beta = 0.76 | total = 149.0189 | recon = 143.7256 | kl = 6.9731
MLP-VAE | epoch 06 | beta = 0.94 | total = 161.2481 | recon = 155.7878 | kl = 5.8314
CNN-beta-VAE | epoch 06 | beta = 0.94 | total = 148.7270 | recon = 142.5082 | kl = 6.6414
MLP-VAE | epoch 07 | beta = 1.11 | total = 159.9874 | recon = 153.6906 | kl = 5.6542
CNN-beta-VAE | epoch 07 | beta = 1.11 | total = 148.6181 | recon = 141.5224 | kl = 6.3717
MLP-VAE | epoch 08 | beta = 1.29 | total = 159.0185 | recon = 151.9687 | kl = 5.4611
CNN-beta-VAE | epoch 08 | beta = 1.29 | total = 148.8237 | recon = 140.8106 | kl = 6.2074
MLP-VAE | epoch 09 | beta = 1.47 | total = 157.9701 | recon = 150.1061 | kl = 5.3563
CNN-beta-VAE | epoch 09 | beta = 1.47 | total = 149.2058 | recon = 140.3045 | kl = 6.0628
MLP-VAE | epoch 10 | beta = 1.65 | total = 157.7816 | recon = 149.2083 | kl = 5.2103
CNN-beta-VAE | epoch 10 | beta = 1.65 | total = 149.8903 | recon = 140.1368 | kl = 5.9275
MLP-VAE | epoch 11 | beta = 1.82 | total = 157.4498 | recon = 148.0400 | kl = 5.1625
CNN-beta-VAE | epoch 11 | beta = 1.82 | total = 150.0761 | recon = 139.4814 | kl = 5.8125
MLP-VAE | epoch 12 | beta = 2.00 | total = 157.2225 | recon = 146.9949 | kl = 5.1138
CNN-beta-VAE | epoch 12 | beta = 2.00 | total = 150.5226 | recon = 139.1076 | kl = 5.7075
MLP-VAE | epoch 13 | beta = 2.00 | total = 156.4221 | recon = 146.1809 | kl = 5.1206
CNN-beta-VAE | epoch 13 | beta = 2.00 | total = 150.2507 | recon = 138.8683 | kl = 5.6912
MLP-VAE | epoch 14 | beta = 2.00 | total = 155.7158 | recon = 145.4732 | kl = 5.1213
CNN-beta-VAE | epoch 14 | beta = 2.00 | total = 149.8739 | recon = 138.4703 | kl = 5.7018
MLP-VAE | epoch 15 | beta = 2.00 | total = 154.8381 | recon = 144.5000 | kl = 5.1690
CNN-beta-VAE | epoch 15 | beta = 2.00 | total = 149.5707 | recon = 138.1323 | kl = 5.7192
MLP-VAE | epoch 16 | beta = 2.00 | total = 154.4008 | recon = 144.0752 | kl = 5.1628
CNN-beta-VAE | epoch 16 | beta = 2.00 | total = 149.1124 | recon = 137.6232 | kl = 5.7446
MLP-VAE | epoch 17 | beta = 2.00 | total = 153.5494 | recon = 143.1642 | kl = 5.1926
CNN-beta-VAE | epoch 17 | beta = 2.00 | total = 148.8510 | recon = 137.3844 | kl = 5.7333
MLP-VAE | epoch 18 | beta = 2.00 | total = 153.3042 | recon = 142.8763 | kl = 5.2140
CNN-beta-VAE | epoch 18 | beta = 2.00 | total = 148.5090 | recon = 137.0037 | kl = 5.7526
MLP-VAE | epoch 19 | beta = 2.00 | total = 152.4354 | recon = 141.9325 | kl = 5.2515
CNN-beta-VAE | epoch 19 | beta = 2.00 | total = 148.3070 | recon = 136.7985 | kl = 5.7542
MLP-VAE | epoch 20 | beta = 2.00 | total = 152.4024 | recon = 141.8576 | kl = 5.2724
CNN-beta-VAE | epoch 20 | beta = 2.00 | total = 148.0397 | recon = 136.4506 | kl = 5.7945
MLP-VAE | epoch 21 | beta = 2.00 | total = 151.6372 | recon = 141.0817 | kl = 5.2778
CNN-beta-VAE | epoch 21 | beta = 2.00 | total = 147.6576 | recon = 136.0964 | kl = 5.7806
MLP-VAE | epoch 22 | beta = 2.00 | total = 151.1195 | recon = 140.5172 | kl = 5.3012
CNN-beta-VAE | epoch 22 | beta = 2.00 | total = 147.5475 | recon = 135.9732 | kl = 5.7871
MLP-VAE | epoch 23 | beta = 2.00 | total = 150.5669 | recon = 139.8465 | kl = 5.3602
CNN-beta-VAE | epoch 23 | beta = 2.00 | total = 147.2031 | recon = 135.6348 | kl = 5.7841
MLP-VAE | epoch 24 | beta = 2.00 | total = 150.2919 | recon = 139.5346 | kl = 5.3786
CNN-beta-VAE | epoch 24 | beta = 2.00 | total = 146.9391 | recon = 135.2944 | kl = 5.8223
MLP-VAE | epoch 25 | beta = 2.00 | total = 150.1169 | recon = 139.3462 | kl = 5.3854
CNN-beta-VAE | epoch 25 | beta = 2.00 | total = 146.9808 | recon = 135.3373 | kl = 5.8218
MLP-VAE | epoch 26 | beta = 2.00 | total = 149.5244 | recon = 138.7132 | kl = 5.4056
CNN-beta-VAE | epoch 26 | beta = 2.00 | total = 146.7464 | recon = 135.1583 | kl = 5.7941
MLP-VAE | epoch 27 | beta = 2.00 | total = 149.6132 | recon = 138.7594 | kl = 5.4269
CNN-beta-VAE | epoch 27 | beta = 2.00 | total = 146.7581 | recon = 135.1271 | kl = 5.8155
MLP-VAE | epoch 28 | beta = 2.00 | total = 148.9314 | recon = 138.0086 | kl = 5.4614
CNN-beta-VAE | epoch 28 | beta = 2.00 | total = 146.6762 | recon = 135.0043 | kl = 5.8359
fig, axes = plt.subplots(1, 2, figsize=(12, 4), sharey=True)
for ax, (name, history) in zip(axes, histories.items()):
ax.plot(history["total"], marker="o", label="total")
ax.plot(history["recon"], marker="s", label="recon")
ax.plot(history["kl"], marker="^", label="KL")
ax.set_xlabel("epoch")
ax.set_title(f"Entrenamiento del {name}")
ax.grid(alpha=0.3)
ax.legend()
ax_beta = ax.twinx()
ax_beta.plot(history["beta"], color="black", linestyle="--", alpha=0.35, label="beta")
ax_beta.set_ylabel("beta", color="black")
ax_beta.tick_params(axis="y", colors="black")
axes[0].set_ylabel("loss")
plt.tight_layout()
plt.show()
@torch.no_grad()
def show_vae_reconstructions(model, loader, title, n=8):
model.eval()
x, _ = next(iter(loader))
x = x.to(DEVICE)
mu, logvar = model.encode(x)
logits = model.decode(mu)
x_hat = torch.sigmoid(logits)
fig, axes = plt.subplots(2, n, figsize=(1.6 * n, 3.2))
for i in range(n):
axes[0, i].imshow(x[i, 0].cpu(), cmap="gray")
axes[0, i].axis("off")
axes[1, i].imshow(x_hat[i, 0].cpu(), cmap="gray")
axes[1, i].axis("off")
axes[0, 0].set_ylabel("original", fontsize=11)
axes[1, 0].set_ylabel("recon", fontsize=11)
fig.suptitle(title)
plt.tight_layout()
plt.show()
show_vae_reconstructions(mlp_vae, test_loader, title="MLP-VAE: reconstrucciones usando la media latente")
show_vae_reconstructions(cnn_vae, test_loader, title="CNN-beta-VAE: reconstrucciones usando la media latente")


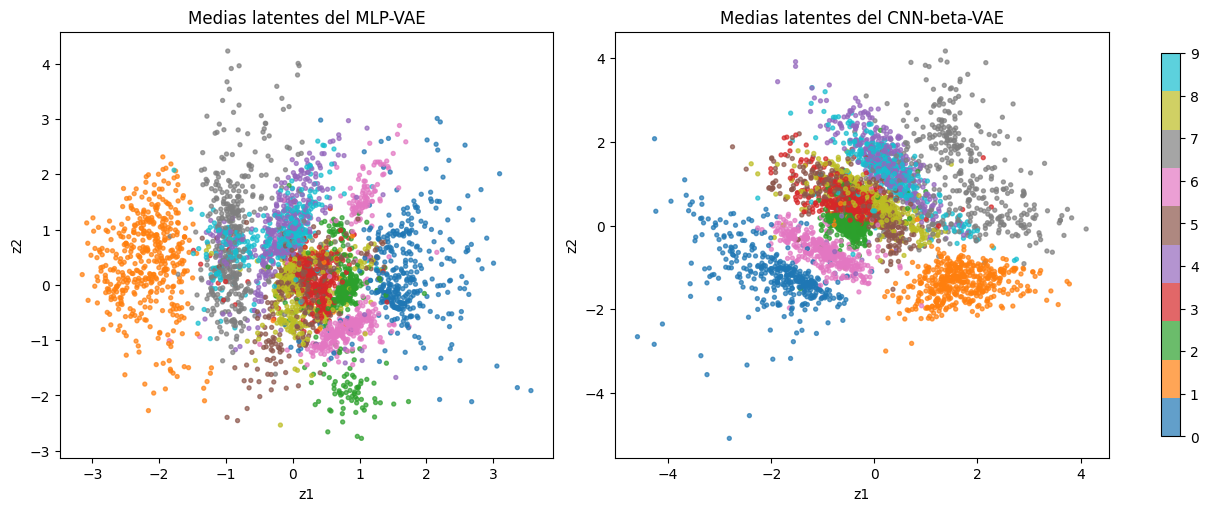
Espacio latente de ambos VAE#
Como elegimos un latente bidimensional, podemos visualizar directamente las medias mu(x) aprendidas por el encoder.
En esta versión conviene mirar especialmente el CNN-beta-VAE:
la arquitectura convolucional mejora la calidad de las características;
el
betacreciente empuja más la organización del latente;el warmup evita que esa regularización destruya la reconstrucción al comienzo del entrenamiento.
No esperamos una separación perfecta por clase, porque el modelo sigue siendo no supervisado, pero sí una estructura más suave y regiones más diferenciadas.
@torch.no_grad()
def collect_latent_means(model, loader):
model.eval()
mus = []
ys = []
for x, y in loader:
x = x.to(DEVICE)
mu, logvar = model.encode(x)
mus.append(mu.cpu())
ys.append(y)
return torch.cat(mus), torch.cat(ys)
latent_results = {
name: collect_latent_means(bundle["model"], test_loader)
for name, bundle in models.items()
}
fig, axes = plt.subplots(1, 2, figsize=(12, 5), constrained_layout=True)
scatter = None
for ax, (name, (latent_mu, latent_y)) in zip(axes, latent_results.items()):
scatter = ax.scatter(latent_mu[:, 0], latent_mu[:, 1], c=latent_y, cmap="tab10", s=8, alpha=0.7)
ax.set_xlabel("z1")
ax.set_ylabel("z2")
ax.set_title(f"Medias latentes del {name}")
fig.colorbar(scatter, ax=axes.ravel().tolist(), shrink=0.9)
plt.show()
@torch.no_grad()
def interpolate_cnn_vae(model, x_start, x_end, steps=10):
model.eval()
x_start = x_start.unsqueeze(0).to(DEVICE)
x_end = x_end.unsqueeze(0).to(DEVICE)
mu_start, _ = model.encode(x_start)
mu_end, _ = model.encode(x_end)
alphas = torch.linspace(0.0, 1.0, steps, device=DEVICE).view(-1, 1)
z_interp = mu_start * (1 - alphas) + mu_end * alphas
logits = model.decode(z_interp)
return torch.sigmoid(logits).cpu()
x_batch, y_batch = next(iter(test_loader))
idx_start, idx_end = 0, 7
x_start = x_batch[idx_start]
x_end = x_batch[idx_end]
interp_images = interpolate_cnn_vae(cnn_vae, x_start, x_end, steps=10)
fig, axes = plt.subplots(1, interp_images.size(0) + 2, figsize=(14, 2.5))
axes[0].imshow(x_start.squeeze(0), cmap="gray")
axes[0].set_title(f"start: {y_batch[idx_start].item()}")
axes[0].axis("off")
for i, img in enumerate(interp_images):
axes[i + 1].imshow(img[0], cmap="gray")
axes[i + 1].axis("off")
axes[-1].imshow(x_end.squeeze(0), cmap="gray")
axes[-1].set_title(f"end: {y_batch[idx_end].item()}")
axes[-1].axis("off")
fig.suptitle("Interpolación en el espacio latente del CNN-beta-VAE")
plt.tight_layout()
plt.show()

Generación de nuevas muestras#
Ahora sí tiene sentido muestrear desde el prior:
Luego decodificamos esos puntos para obtener nuevas imágenes. Esta operación es mucho más natural en un VAE que en un AE clásico, justamente porque el entrenamiento regularizó el espacio latente. Abajo comparamos las muestras del MLP-VAE y del CNN-VAE.
@torch.no_grad()
def sample_from_vae(model, n=16):
model.eval()
z = torch.randn(n, model.latent_dim, device=DEVICE)
logits = model.decode(z)
return torch.sigmoid(logits).cpu()
fig, axes = plt.subplots(2, 8, figsize=(10, 4))
for row, (name, bundle) in enumerate(models.items()):
samples = sample_from_vae(bundle["model"], n=8)
for col, img in enumerate(samples):
axes[row, col].imshow(img[0], cmap="gray")
axes[row, col].axis("off")
axes[row, 0].set_ylabel(name, fontsize=11)
fig.suptitle("Muestras generadas desde z ~ N(0, I)")
plt.tight_layout()
plt.show()

@torch.no_grad()
def latent_grid(model, grid_size=12, span=2.5):
model.eval()
coords = torch.linspace(-span, span, grid_size)
canvas = torch.zeros(28 * grid_size, 28 * grid_size)
for i, y in enumerate(reversed(coords)):
for j, x in enumerate(coords):
z = torch.tensor([[x, y]], dtype=torch.float32, device=DEVICE)
img = torch.sigmoid(model.decode(z))[0, 0].cpu()
canvas[i * 28:(i + 1) * 28, j * 28:(j + 1) * 28] = img
return canvas
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
for ax, (name, bundle) in zip(axes, models.items()):
ax.imshow(latent_grid(bundle["model"]), cmap="gray")
ax.set_title(f"Recorrido del espacio latente: {name}")
ax.axis("off")
plt.tight_layout()
plt.show()
