Optimización Bayesiana de hiperparámetros#
![]()
!pip install -q deepxde
import os
# necesario para obligar a deepxde a usar el framework de pytorch.
os.environ['DDE_BACKEND'] = "pytorch"
import deepxde as dde
from matplotlib import pyplot as plt
import numpy as np
import skopt
from skopt import gp_minimize
from skopt.plots import plot_convergence, plot_objective
from skopt.space import Real, Categorical, Integer
from skopt.utils import use_named_args
import torch
torch.set_default_device("cpu")
if dde.backend.backend_name == "pytorch":
sin = dde.backend.pytorch.sin
pi = torch.pi
elif dde.backend.backend_name == "paddle":
sin = dde.backend.paddle.sin
else:
from deepxde.backend import tf
sin = tf.sin
pi = tf.constant(np.pi, dtype=tf.float32)
Introducción#
En esta notebook vamos a resolver el problema de inversión para la ecuación de Poisson 1D en donde no conocemos el campo de fuerza, i.e.
La función pde(x, y) define el residuo físico que la red debe minimizar. Para eso calcula la segunda derivada de la salida respecto de la entrada, \(u''(x)\), y arma el residuo de la ecuación.
La función sol_exacta(x) no se usa para entrenar directamente toda la solución, sino como referencia para:
generar algunos datos observados,
evaluar el error de prueba,
comparar la solución aproximada con la exacta al final.
def pde(x, y):
u, q = y[:, 0:1], y[:,1:2] #ambas u y q son desconocidas
dy_xx = dde.grad.hessian(y, x, component=0, i=0, j=0)
return dy_xx - q
def sol_exacta(x):
return np.sin(np.pi * x)
Condiciones de contorno y datos observados#
Acá se construyen las restricciones que acompañan a la ecuación, exactamente como hemos hecho antes:
contornoidentifica si un punto pertenece al borde del dominio.func_contornofija el valor de la solución en el contorno, en este caso \(u=0\).x_trainyy_trainagregan puntos observados dentro del dominio, lo que ayuda a guiar el entrenamiento de la PINN.
# auxiliar para los puntos en el contorno
def contorno(x, en_contorno):
return en_contorno
# función auxiliar para los valores en el contorno
def func_contorno(x):
return 0
Supongamos que tenemos solo los datos de entrenamiento en puntos equiespaciados entre -1 y 0.
x_train = np.linspace(-1, 0, 10).reshape(-1, 1)
y_train = sol_exacta(x_train)
geom = dde.geometry.Interval(-1, 1)
observe_u = dde.icbc.PointSetBC(x_train, y_train, component=0)
bc = dde.DirichletBC(geom, func_contorno, contorno)
Construcción del modelo PINN#
La función create_model(config) recibe una configuración de hiperparámetros y arma una PINN completa. En esta etapa se definen:
el objeto
data, que contiene la ecuación diferencial, las condiciones y la discretización del dominio;la arquitectura de la red neuronal totalmente conectada;
el optimizador Adam y la métrica de error relativo \(L^2\).
Esto es importante porque la optimización bayesiana va a probar muchas configuraciones distintas, y en cada intento necesita reconstruir el modelo con otros hiperparámetros.
def create_model(config):
learning_rate, num_dense_layers, num_dense_nodes, activation = config
data = dde.data.PDE(
geom,
pde,
[observe_u, bc],
num_domain=16,
num_boundary=2,
solution=sol_exacta,
# anchors=x_train,
num_test=100,
)
net = dde.maps.FNN(
[1] + [num_dense_nodes] * num_dense_layers + [2],
activation,
"Glorot uniform",
)
model = dde.Model(data, net)
model.compile("adam", lr=learning_rate, metrics=["l2 relative error"])
return model, data
Entrenamiento y función de costo#
train_model ejecuta el entrenamiento durante un número fijo de iteraciones y recupera el historial de pérdidas. El valor que finalmente se devuelve como error es el mínimo de la pérdida de prueba.
Ese escalar resume qué tan bien funcionó una configuración dada y será la cantidad que la optimización bayesiana intentará minimizar.
def train_model(model, config, iterations=4000):
losshistory, train_state = model.train(iterations=iterations)
train = np.array(losshistory.loss_train).sum(axis=1).ravel()
test = np.array(losshistory.loss_test).sum(axis=1).ravel()
metric = np.array(losshistory.metrics_test).sum(axis=1).ravel()
error = test.min()
return error, losshistory, train_state
Espacio de búsqueda de hiperparámetros#
En esta sección se define qué aspectos del modelo se van a optimizar:
learning_rate: tasa de aprendizaje del optimizador.num_dense_layers: cantidad de capas ocultas.num_dense_nodes: cantidad de neuronas por capa.activation: función de activación.
También se fija default_parameters, que sirve como punto inicial conocido para arrancar la búsqueda. Este espacio mezcla variables continuas, enteras y categóricas, algo que skopt maneja de forma directa.
n_calls = 15
dim_learning_rate = Real(low=1e-4, high=5e-2, name="learning_rate", prior="log-uniform")
dim_num_dense_layers = Integer(low=1, high=6, name="num_dense_layers")
dim_num_dense_nodes = Integer(low=5, high=50, name="num_dense_nodes")
dim_activation = Categorical(categories=["sin", "sigmoid", "tanh"], name="activation")
dimensions = [
dim_learning_rate,
dim_num_dense_layers,
dim_num_dense_nodes,
dim_activation,
]
default_parameters = [1e-3, 4, 50, "sin"]
Función objetivo para la optimización bayesiana#
La función fitness(...) es la interfaz entre la PINN y el optimizador bayesiano. Para cada conjunto de hiperparámetros:
arma una configuración,
crea el modelo correspondiente,
lo entrena,
devuelve el error obtenido.
@use_named_args permite que skopt pase los parámetros en forma clara según los nombres definidos en dimensions. Además, si aparece un NaN, se reemplaza por una penalización grande para que esa configuración quede descartada por el algoritmo.
@use_named_args(dimensions=dimensions)
def fitness(learning_rate, num_dense_layers, num_dense_nodes, activation):
config = [learning_rate, num_dense_layers, num_dense_nodes, activation]
global ITERATION
print(ITERATION, "it number")
# Print the hyper-parameters.
print("learning rate: {0:.1e}".format(learning_rate))
print("num_dense_layers:", num_dense_layers)
print("num_dense_nodes:", num_dense_nodes)
print("activation:", activation)
print()
# Create the neural network with these hyper-parameters.
model, _ = create_model(config)
# possibility to change where we save
error, _, _ = train_model(model, config)
# print(accuracy, 'accuracy is')
if np.isnan(error):
error = 10**5
ITERATION += 1
return error
Búsqueda bayesiana de la mejor configuración#
gp_minimize implementa la optimización bayesiana modelando la función objetivo con un proceso gaussiano. En cada iteración usa la información acumulada de evaluaciones anteriores para decidir qué combinación probar después.
La función de adquisición EI (Expected Improvement) favorece puntos que prometen mejorar el mejor resultado actual, equilibrando exploración y explotación. Al terminar, search_result.x contiene los mejores hiperparámetros encontrados y search_result.fun el mejor error asociado.
ITERATION = 0
search_result = gp_minimize(
func=fitness,
dimensions=dimensions,
acq_func="EI", # Expected Improvement.
n_calls=n_calls,
x0=default_parameters,
random_state=1234,
)
best_params = search_result.x
best_score = search_result.fun
0 it number
learning rate: 1.0e-03
num_dense_layers: 4
num_dense_nodes: 50
activation: sin
Compiling model...
'compile' took 0.000084 s
Training model...
Step Train loss Test loss Test metric
0 [3.81e-02, 5.33e-01, 1.81e-02] [3.14e-02, 5.33e-01, 1.81e-02] [1.36e+00]
1000 [2.34e-03, 1.60e-03, 4.52e-06] [2.00e-03, 1.60e-03, 4.52e-06] [1.06e+01]
2000 [1.65e-04, 5.57e-04, 1.41e-05] [1.76e-04, 5.57e-04, 1.41e-05] [1.08e+01]
3000 [2.69e-04, 3.07e-04, 1.07e-05] [2.83e-04, 3.07e-04, 1.07e-05] [1.10e+01]
4000 [1.17e-03, 2.65e-04, 8.16e-06] [1.05e-03, 2.65e-04, 8.16e-06] [1.09e+01]
Best model at step 3000:
train loss: 5.87e-04
test loss: 6.00e-04
test metric: [1.10e+01]
'train' took 8.067976 s
1 it number
learning rate: 2.2e-03
num_dense_layers: 5
num_dense_nodes: 33
activation: tanh
Compiling model...
'compile' took 0.000094 s
Training model...
Step Train loss Test loss Test metric
0 [1.99e-02, 5.23e-01, 1.29e-02] [1.69e-02, 5.23e-01, 1.29e-02] [1.55e+00]
1000 [4.07e-03, 1.74e-03, 6.49e-04] [5.39e-03, 1.74e-03, 6.49e-04] [9.97e+00]
2000 [1.09e-04, 1.24e-03, 4.57e-05] [4.28e-03, 1.24e-03, 4.57e-05] [1.03e+01]
3000 [2.74e-03, 1.30e-03, 1.29e-03] [5.79e-03, 1.30e-03, 1.29e-03] [1.03e+01]
4000 [6.50e-03, 1.74e-03, 3.19e-04] [8.16e-03, 1.74e-03, 3.19e-04] [1.04e+01]
Best model at step 2000:
train loss: 1.40e-03
test loss: 5.57e-03
test metric: [1.03e+01]
'train' took 7.748544 s
2 it number
learning rate: 2.1e-02
num_dense_layers: 2
num_dense_nodes: 14
activation: tanh
Compiling model...
'compile' took 0.000237 s
Training model...
Step Train loss Test loss Test metric
0 [2.42e+00, 1.51e+00, 9.93e-01] [2.20e+00, 1.51e+00, 9.93e-01] [2.71e+00]
1000 [1.04e-03, 3.21e-03, 1.69e-04] [9.12e-04, 3.21e-03, 1.69e-04] [9.18e+00]
2000 [1.02e-03, 1.64e-03, 1.84e-04] [2.96e-03, 1.64e-03, 1.84e-04] [9.79e+00]
3000 [3.10e-02, 1.50e-03, 1.60e-04] [3.38e-02, 1.50e-03, 1.60e-04] [1.01e+01]
4000 [2.81e-02, 1.17e-03, 3.49e-04] [2.93e-02, 1.17e-03, 3.49e-04] [1.03e+01]
Best model at step 2000:
train loss: 2.85e-03
test loss: 4.78e-03
test metric: [9.79e+00]
'train' took 4.108662 s
3 it number
learning rate: 2.7e-04
num_dense_layers: 2
num_dense_nodes: 6
activation: sigmoid
Compiling model...
'compile' took 0.000083 s
Training model...
Step Train loss Test loss Test metric
0 [1.12e-01, 1.94e-01, 6.89e-01] [1.12e-01, 1.94e-01, 6.89e-01] [1.88e+00]
1000 [4.79e-04, 2.05e-01, 7.69e-02] [3.99e-04, 2.05e-01, 7.69e-02] [1.42e+00]
2000 [1.35e-03, 2.01e-01, 7.52e-02] [1.15e-03, 2.01e-01, 7.52e-02] [1.40e+00]
3000 [1.76e-03, 1.95e-01, 7.53e-02] [1.55e-03, 1.95e-01, 7.53e-02] [1.39e+00]
4000 [1.43e-03, 1.89e-01, 7.52e-02] [1.34e-03, 1.89e-01, 7.52e-02] [1.40e+00]
Best model at step 4000:
train loss: 2.66e-01
test loss: 2.66e-01
test metric: [1.40e+00]
'train' took 4.716254 s
4 it number
learning rate: 7.8e-04
num_dense_layers: 5
num_dense_nodes: 9
activation: sin
Compiling model...
'compile' took 0.000085 s
Training model...
Step Train loss Test loss Test metric
0 [7.37e-04, 6.67e-01, 8.74e-02] [8.31e-04, 6.67e-01, 8.74e-02] [1.50e+00]
1000 [2.51e-03, 3.15e-02, 3.10e-03] [1.94e-03, 3.15e-02, 3.10e-03] [6.29e+00]
2000 [9.54e-04, 2.38e-03, 3.59e-05] [9.02e-04, 2.38e-03, 3.59e-05] [9.31e+00]
3000 [2.98e-04, 7.69e-04, 1.30e-05] [3.14e-04, 7.69e-04, 1.30e-05] [9.82e+00]
4000 [1.74e-04, 4.41e-04, 1.60e-05] [1.97e-04, 4.41e-04, 1.60e-05] [9.97e+00]
Best model at step 4000:
train loss: 6.30e-04
test loss: 6.54e-04
test metric: [9.97e+00]
'train' took 7.182047 s
5 it number
learning rate: 1.6e-03
num_dense_layers: 1
num_dense_nodes: 18
activation: sin
Compiling model...
'compile' took 0.000063 s
Training model...
Step Train loss Test loss Test metric
0 [3.30e-03, 2.59e-01, 1.97e-01] [2.75e-03, 2.59e-01, 1.97e-01] [1.31e+00]
1000 [2.06e-03, 6.60e-02, 4.58e-03] [1.67e-03, 6.60e-02, 4.58e-03] [4.59e+00]
2000 [3.81e-04, 2.56e-03, 1.04e-04] [3.08e-04, 2.56e-03, 1.04e-04] [1.15e+01]
3000 [1.45e-04, 2.35e-03, 1.22e-04] [1.19e-04, 2.35e-03, 1.22e-04] [1.16e+01]
4000 [6.22e-05, 2.03e-03, 1.08e-04] [5.20e-05, 2.03e-03, 1.08e-04] [1.16e+01]
Best model at step 4000:
train loss: 2.20e-03
test loss: 2.19e-03
test metric: [1.16e+01]
'train' took 3.129777 s
6 it number
learning rate: 9.8e-03
num_dense_layers: 5
num_dense_nodes: 49
activation: sin
Compiling model...
'compile' took 0.000076 s
Training model...
Step Train loss Test loss Test metric
0 [1.57e-01, 5.07e-01, 9.38e-03] [1.28e-01, 5.07e-01, 9.38e-03] [1.80e+00]
1000 [8.39e-03, 1.12e-01, 1.48e-02] [7.92e-03, 1.12e-01, 1.48e-02] [2.56e+00]
2000 [1.09e-03, 4.17e-02, 3.61e-03] [8.99e-04, 4.17e-02, 3.61e-03] [4.95e+00]
3000 [8.77e-04, 1.50e-02, 8.92e-04] [7.17e-04, 1.50e-02, 8.92e-04] [6.75e+00]
4000 [4.11e-04, 8.19e-04, 1.15e-06] [4.21e-04, 8.19e-04, 1.15e-06] [9.16e+00]
Best model at step 4000:
train loss: 1.23e-03
test loss: 1.24e-03
test metric: [9.16e+00]
'train' took 9.776608 s
7 it number
learning rate: 1.2e-03
num_dense_layers: 3
num_dense_nodes: 29
activation: tanh
Compiling model...
'compile' took 0.000096 s
Training model...
Step Train loss Test loss Test metric
0 [1.23e-01, 3.73e-01, 1.54e-02] [1.07e-01, 3.73e-01, 1.54e-02] [1.19e+00]
1000 [3.85e-04, 1.36e-03, 4.73e-05] [4.59e-04, 1.36e-03, 4.73e-05] [1.09e+01]
2000 [1.07e-03, 1.91e-03, 1.49e-04] [1.28e-03, 1.91e-03, 1.49e-04] [1.10e+01]
3000 [5.64e-04, 1.04e-03, 5.57e-04] [1.16e-03, 1.04e-03, 5.57e-04] [1.11e+01]
4000 [1.53e-04, 9.17e-04, 5.50e-05] [1.20e-03, 9.17e-04, 5.50e-05] [1.11e+01]
Best model at step 4000:
train loss: 1.13e-03
test loss: 2.17e-03
test metric: [1.11e+01]
'train' took 5.681351 s
8 it number
learning rate: 1.8e-03
num_dense_layers: 3
num_dense_nodes: 31
activation: tanh
Compiling model...
'compile' took 0.000089 s
Training model...
Step Train loss Test loss Test metric
0 [1.30e-03, 4.69e-01, 4.74e-04] [1.36e-03, 4.69e-01, 4.74e-04] [1.42e+00]
1000 [5.04e-04, 2.66e-03, 1.94e-04] [7.12e-04, 2.66e-03, 1.94e-04] [1.02e+01]
2000 [1.55e-04, 1.68e-03, 1.53e-04] [1.75e-03, 1.68e-03, 1.53e-04] [1.06e+01]
3000 [6.12e-04, 1.32e-03, 3.40e-04] [4.65e-03, 1.32e-03, 3.40e-04] [1.07e+01]
4000 [1.11e-04, 1.12e-03, 5.69e-05] [5.79e-03, 1.12e-03, 5.69e-05] [1.08e+01]
Best model at step 4000:
train loss: 1.29e-03
test loss: 6.97e-03
test metric: [1.08e+01]
'train' took 5.678634 s
9 it number
learning rate: 1.3e-04
num_dense_layers: 4
num_dense_nodes: 26
activation: sigmoid
Compiling model...
'compile' took 0.000090 s
Training model...
Step Train loss Test loss Test metric
0 [1.29e-01, 4.03e-01, 1.84e-03] [1.29e-01, 4.03e-01, 1.84e-03] [1.53e+00]
1000 [2.95e-06, 2.08e-01, 7.95e-02] [2.38e-06, 2.08e-01, 7.95e-02] [1.45e+00]
2000 [1.05e-03, 1.87e-01, 7.52e-02] [8.47e-04, 1.87e-01, 7.52e-02] [1.44e+00]
3000 [3.17e-03, 1.74e-01, 7.02e-02] [2.78e-03, 1.74e-01, 7.02e-02] [1.41e+00]
4000 [4.78e-03, 1.27e-01, 2.21e-02] [3.28e-03, 1.27e-01, 2.21e-02] [1.93e+00]
Best model at step 4000:
train loss: 1.54e-01
test loss: 1.53e-01
test metric: [1.93e+00]
'train' took 6.819471 s
10 it number
learning rate: 7.7e-04
num_dense_layers: 5
num_dense_nodes: 34
activation: sin
Compiling model...
'compile' took 0.000075 s
Training model...
Step Train loss Test loss Test metric
0 [4.13e-02, 4.18e-01, 2.29e-03] [3.54e-02, 4.18e-01, 2.29e-03] [1.29e+00]
1000 [3.23e-04, 1.27e-03, 1.09e-05] [3.37e-04, 1.27e-03, 1.09e-05] [1.08e+01]
2000 [9.34e-06, 5.24e-04, 2.74e-05] [1.32e-05, 5.24e-04, 2.74e-05] [1.11e+01]
3000 [6.68e-06, 3.18e-04, 1.50e-05] [1.11e-05, 3.18e-04, 1.50e-05] [1.11e+01]
4000 [4.98e-03, 3.19e-04, 1.69e-04] [5.65e-03, 3.19e-04, 1.69e-04] [1.11e+01]
Best model at step 3000:
train loss: 3.39e-04
test loss: 3.44e-04
test metric: [1.11e+01]
'train' took 7.652172 s
11 it number
learning rate: 2.0e-02
num_dense_layers: 6
num_dense_nodes: 50
activation: sigmoid
Compiling model...
'compile' took 0.000152 s
Training model...
Step Train loss Test loss Test metric
0 [4.15e-01, 2.03e-01, 7.07e-01] [4.15e-01, 2.03e-01, 7.07e-01] [1.99e+00]
1000 [2.23e-03, 1.24e-01, 8.75e-03] [2.18e-03, 1.24e-01, 8.75e-03] [2.55e+00]
2000 [1.90e-03, 6.78e-02, 4.97e-03] [1.81e-03, 6.78e-02, 4.97e-03] [4.04e+00]
3000 [3.01e-04, 2.92e-02, 1.46e-03] [2.69e-04, 2.92e-02, 1.46e-03] [6.16e+00]
4000 [7.99e-02, 2.36e-02, 1.63e-02] [8.73e-02, 2.36e-02, 1.63e-02] [7.01e+00]
Best model at step 3000:
train loss: 3.10e-02
test loss: 3.10e-02
test metric: [6.16e+00]
'train' took 11.215365 s
12 it number
learning rate: 1.0e-04
num_dense_layers: 1
num_dense_nodes: 5
activation: tanh
Compiling model...
'compile' took 0.000100 s
Training model...
Step Train loss Test loss Test metric
0 [4.86e-02, 1.15e+00, 5.97e-01] [4.60e-02, 1.15e+00, 5.97e-01] [1.83e+00]
1000 [1.38e-03, 3.53e-01, 2.27e-01] [1.07e-03, 3.53e-01, 2.27e-01] [1.57e+00]
2000 [4.06e-03, 2.08e-01, 1.22e-01] [3.53e-03, 2.08e-01, 1.22e-01] [1.48e+00]
3000 [2.09e-03, 1.85e-01, 7.80e-02] [1.99e-03, 1.85e-01, 7.80e-02] [1.44e+00]
4000 [1.57e-03, 1.78e-01, 7.31e-02] [1.42e-03, 1.78e-01, 7.31e-02] [1.44e+00]
Best model at step 4000:
train loss: 2.52e-01
test loss: 2.52e-01
test metric: [1.44e+00]
'train' took 3.302646 s
13 it number
learning rate: 1.1e-04
num_dense_layers: 3
num_dense_nodes: 6
activation: sin
Compiling model...
'compile' took 0.000112 s
Training model...
Step Train loss Test loss Test metric
0 [1.30e-01, 6.04e-01, 1.96e-02] [1.37e-01, 6.04e-01, 1.96e-02] [1.44e+00]
1000 [5.07e-03, 1.77e-01, 7.60e-02] [4.60e-03, 1.77e-01, 7.60e-02] [1.34e+00]
2000 [9.23e-03, 1.58e-01, 6.14e-02] [7.61e-03, 1.58e-01, 6.14e-02] [1.52e+00]
3000 [1.16e-02, 1.28e-01, 4.14e-02] [7.77e-03, 1.28e-01, 4.14e-02] [1.91e+00]
4000 [1.05e-02, 1.01e-01, 1.92e-02] [8.20e-03, 1.01e-01, 1.92e-02] [2.66e+00]
Best model at step 4000:
train loss: 1.30e-01
test loss: 1.28e-01
test metric: [2.66e+00]
'train' took 5.418440 s
14 it number
learning rate: 1.1e-04
num_dense_layers: 4
num_dense_nodes: 6
activation: tanh
Compiling model...
'compile' took 0.000119 s
Training model...
Step Train loss Test loss Test metric
0 [4.78e-02, 5.17e-01, 8.81e-03] [4.45e-02, 5.17e-01, 8.81e-03] [1.57e+00]
1000 [8.17e-03, 1.72e-01, 7.15e-02] [7.35e-03, 1.72e-01, 7.15e-02] [1.48e+00]
2000 [8.78e-03, 1.66e-01, 6.89e-02] [7.64e-03, 1.66e-01, 6.89e-02] [1.50e+00]
3000 [9.06e-03, 1.48e-01, 5.72e-02] [7.15e-03, 1.48e-01, 5.72e-02] [1.61e+00]
4000 [7.57e-03, 1.18e-01, 2.79e-02] [5.79e-03, 1.18e-01, 2.79e-02] [2.09e+00]
Best model at step 4000:
train loss: 1.53e-01
test loss: 1.52e-01
test metric: [2.09e+00]
'train' took 6.554475 s
Reentrenamiento con la mejor configuración#
Una vez terminada la búsqueda, se vuelve a crear la PINN usando los hiperparámetros óptimos y se la entrena otra vez. Esto permite disponer del modelo final para hacer predicciones, comparar con la solución exacta y analizar visualmente el resultado.
print("Best params:", best_params)
print("Best score:", best_score)
modelo, data = create_model(best_params)
error, losshistory, train_state = train_model(modelo, best_params, iterations=10000)
Best params: [0.0007674054502520459, 5, 34, 'sin']
Best score: 0.0003437009
Compiling model...
'compile' took 0.000087 s
Training model...
Step Train loss Test loss Test metric
0 [2.67e-02, 5.60e-01, 2.38e-02] [2.38e-02, 5.60e-01, 2.38e-02] [1.53e+00]
1000 [1.15e-04, 7.81e-04, 1.82e-05] [1.04e-04, 7.81e-04, 1.82e-05] [1.09e+01]
2000 [5.00e-04, 5.76e-04, 1.59e-05] [5.76e-04, 5.76e-04, 1.59e-05] [1.11e+01]
3000 [3.24e-05, 4.69e-04, 2.67e-05] [4.63e-05, 4.69e-04, 2.67e-05] [1.12e+01]
4000 [2.12e-05, 4.26e-04, 2.39e-05] [3.28e-05, 4.26e-04, 2.39e-05] [1.12e+01]
5000 [2.14e-04, 3.85e-04, 8.42e-06] [2.17e-04, 3.85e-04, 8.42e-06] [1.12e+01]
6000 [1.33e-05, 3.17e-04, 1.69e-05] [2.39e-05, 3.17e-04, 1.69e-05] [1.12e+01]
7000 [1.05e-05, 2.92e-04, 1.66e-05] [1.95e-05, 2.92e-04, 1.66e-05] [1.12e+01]
8000 [2.24e-05, 2.90e-04, 4.37e-06] [3.35e-05, 2.90e-04, 4.37e-06] [1.12e+01]
9000 [8.82e-06, 2.37e-04, 1.41e-05] [1.51e-05, 2.37e-04, 1.41e-05] [1.12e+01]
10000 [4.15e-03, 2.75e-04, 3.21e-06] [4.70e-03, 2.75e-04, 3.21e-06] [1.12e+01]
Best model at step 9000:
train loss: 2.60e-04
test loss: 2.66e-04
test metric: [1.12e+01]
'train' took 19.793434 s
Evaluación sobre puntos del dominio#
Acá se generan puntos del intervalo para inspeccionar la solución aprendida. Se calculan:
las predicciones en los puntos observados,
las predicciones en una malla más densa del dominio,
los valores exactos para comparar.
Con esto se puede verificar si la red reproduce correctamente la forma esperada de la solución de la PDE.
x = geom.uniform_points(50, True)
X_domain = data.train_x[:data.num_domain]
y_pred_train = modelo.predict(x_train)
y_exact_train = sol_exacta(x_train)
y_pred = modelo.predict(x)
y_exact = sol_exacta(x)
Visualización de la solución y del proceso de optimización#
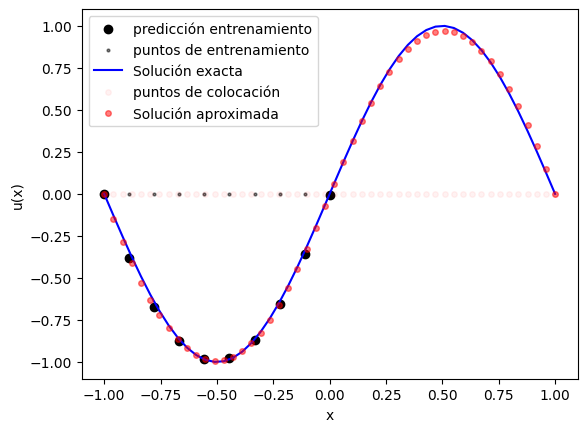
Las últimas celdas muestran dos tipos de resultados:
la comparación entre solución exacta, predicción de la PINN y puntos usados en el entrenamiento;
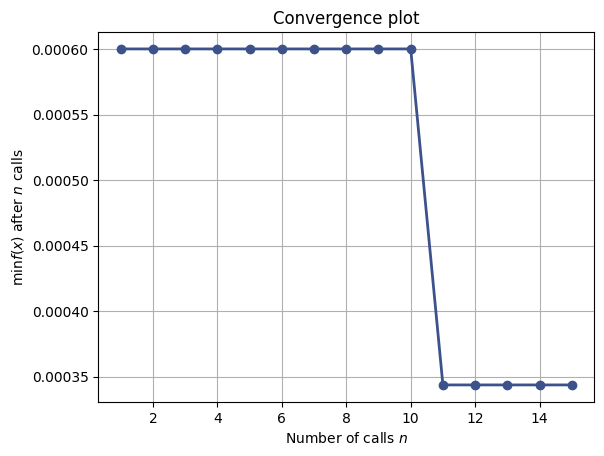
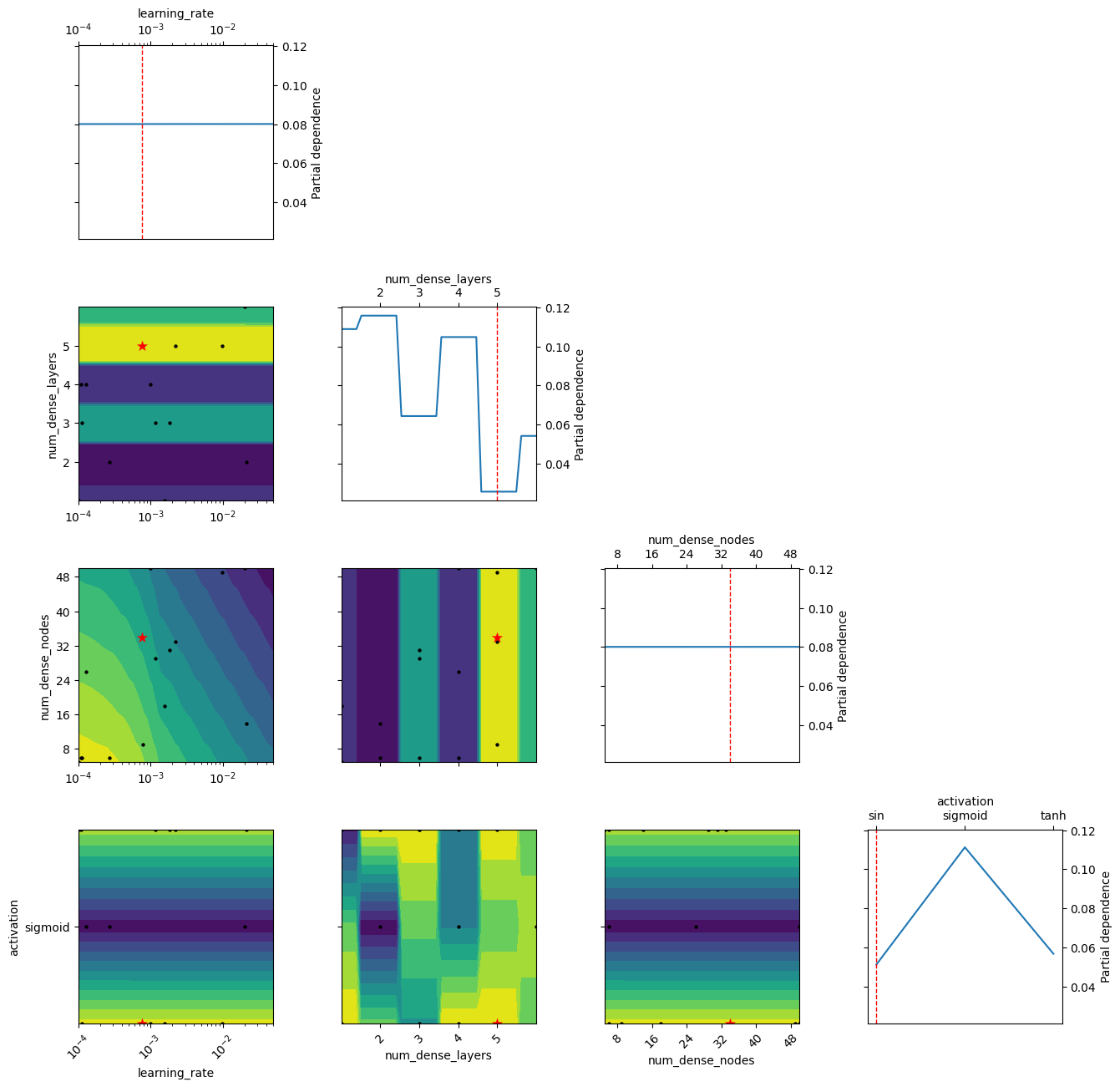
la evolución de la optimización bayesiana mediante
plot_convergenceyplot_objective.
La primera figura sirve para validar la aproximación física. Las otras ayudan a entender si la búsqueda de hiperparámetros convergió y cómo influyó cada variable sobre el desempeño del modelo.
plt.figure()
plt.scatter(x_train, y_pred_train[:,0], color='black', label="predicción entrenamiento")
plt.scatter(x_train, np.zeros_like(x_train), color='black', label="puntos de entrenamiento", alpha=0.5, s=4)
plt.plot(x, y_exact, 'b', label="Solución exacta")
plt.plot(x, np.zeros_like(x), 'or', label="puntos de colocación", alpha=0.05, ms=4)
plt.plot(x, y_pred[:,0], 'or', label="Solución aproximada", alpha=0.5, ms=4)
plt.xlabel("x")
plt.ylabel("u(x)")
plt.legend()
plt.show()
plot_convergence(search_result)
plt.show()
plot_objective(search_result, show_points=True, size=3.8)
plt.show()
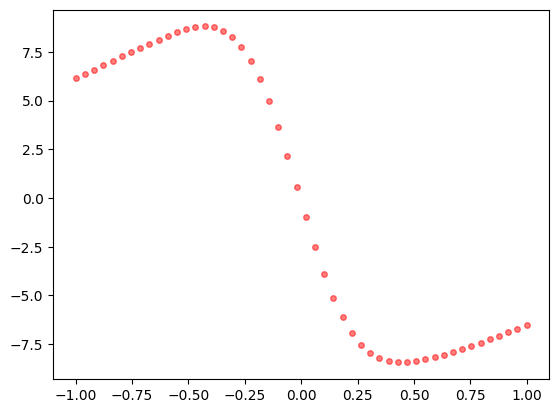
Vemos la estimación del campo de fuerza
plt.plot(x, y_pred[:,1], 'or', label="Solución aproximada", alpha=0.5, ms=4)
plt.show()
[<matplotlib.lines.Line2D at 0x314a0cc20>]